Overview - K2HDKC DBaaS with Trove
K2HDKC DBaaS(Database as a Service for K2HDKC) is based on Trove(Trove is Database as a Service for OpenStack) and works with other OpenStack components.
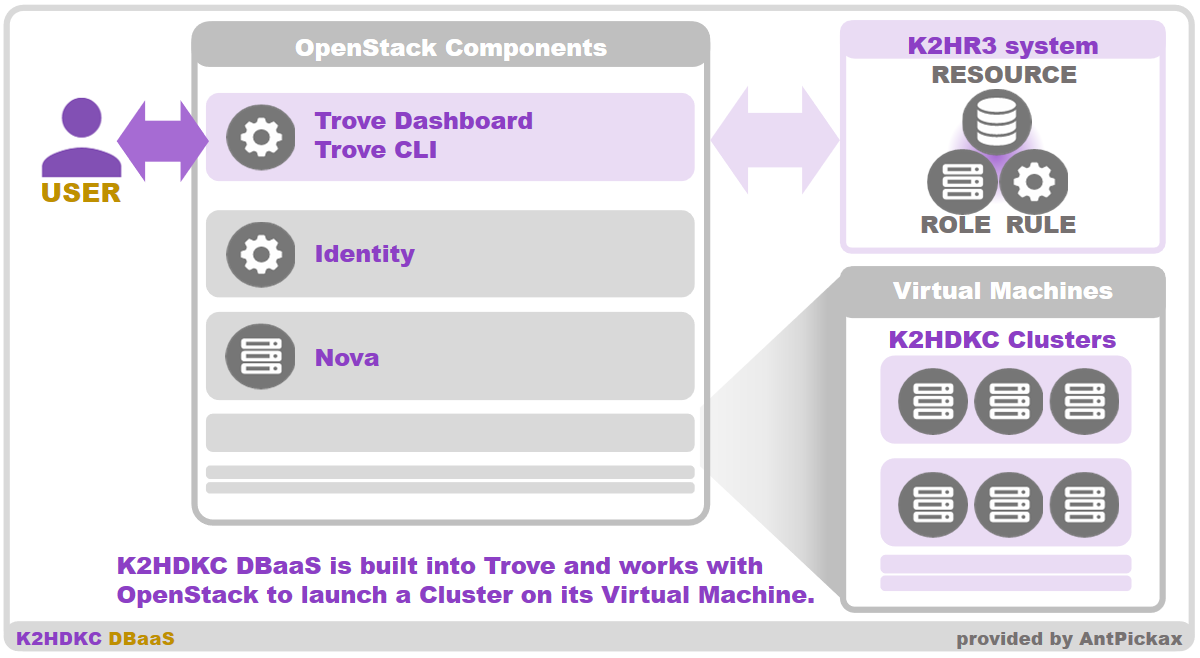
K2HDKC DBaaS K2HDKC cluster construction and operation are performed from Dashboard(Trove Dashboard) or Trove CLI(openstack command).
You can use it to build and remove K2HDKC clusters, add and remove(scale) server nodes in the cluster, and perform backup and restore operations.
K2HDKC DBaaS also supports the construction of K2HDKC slave nodes that can be easily connected to K2HDKC clusters and their automatic configuration.
Below is a brief description of the K2HDKC DBaaS system.
Composition of K2HDKC DBaaS with Trove
The following describes the overview for system of K2HDKC DBaaS with Trove.
About OpenStack components
K2HDKC DBaaS requires OpenStack components.
The system administrator is responsible for building each component of OpenStack and the entire structure.
It is also possible to incorporate K2HDKC DBaaS into existing your OpenStack system.
Trove is one of the OpenStack components, and K2HDKC DBaaS is included as one of that Trove’s Database.
In other words, K2HDKC DBaaS is a system that extends K2HDKC to Trove’s Database type.
The basic specifications of K2HDKC DBaaS all follow Trove, and you can operate and operate K2HDKC cluster as DBaaS by Trove.
K2HR3 system
K2HDKC DBaaS requires the K2HR3 system, which is one of the AntPickax products.
K2HR3 system and Trove work together to provide the DBaaS system.
K2HR3 is designed to work with OpenStack and is used as Trove’s backend system.
K2HR3 system must be built in a network that can be accessed from OpenStack components and instances(Virtual Machine).
For example, you can build K2HR3 system in instances(Virtual Machines) which are created by OpenStack that works for K2HDKC DBaaS.
K2HDKC Clusters
K2HDKC Cluster is a cluster of K2HDKC that is built by user using K2HDKC DBaaS.
K2HDKC cluster is a cluster consisting of multiple K2HDKC server nodes launched on instances(Virtual Machine) managed by OpenStack.
K2HDKC DBaaS builds, destroys, and controls(scales, data merges) these K2HDKC clusters.
K2HDKC server processes are launched as Docker containers in an instance.(K2HDKC DBaaS Trove version 1.0.2 or later, OpenStack Trove stable/2024.1 or later)
K2HDKC Slave nodes
K2HDKC slave node is the client that connects to a K2HDKC cluster(server nodes) created by K2HDKC DBaaS.
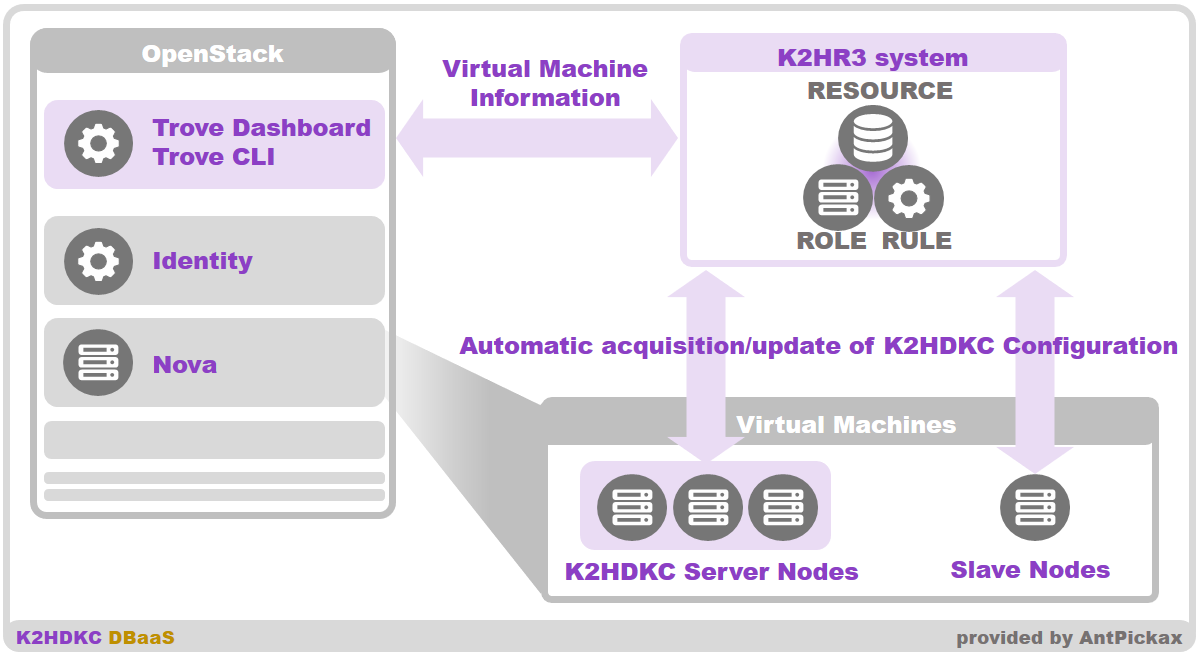
You can manually configure and boot the K2HDKC slave node.
In addition, you can easily boot the K2HDKC slave node and take advantage of automatic configuration by using the features of K2HDKC DBaaS.
When using K2HDKC DBaaS for K2HDKC slave node, you starts an instance(Virtual Machine) of OpenStack linked with K2HDKC DBaaS as a HOST for the slave node of K2HDKC.
When launching this instance(Virtual Machine), you use the User Data Script for OpenStack data provided by K2HR3.
This allows the booted instance(Virtual Machine) to work with the K2HR3 system.
Ultimately, the configuration and all packages needed to connect to the K2HDKC cluster are installed and configured to automate the management of K2HDKC slave nodes.
The K2HDKC slave node in this way can automatically perform processing such as connection/disconnection according to the scale of the K2HDKC server node.
Thus, it hides the configuration of the K2HDK cluster from the user’s program on the K2HDKC slave node.
The user program does not need to be aware of the server node configuration, and the load on developers and operators can be reduced.