使い方 - K2HDKC DBaaS with Trove
Trove(Trove is Database as a Service for OpenStack)と連携するK2HDKC DBaaS with Trove (Database as a Service for K2HDKC)の使い方を説明します。
この K2HDKC DBaaS with Trove (Database as a Service for K2HDKC) は、Trove(Trove is Database as a Service for OpenStack) に組み込まれたシステムであるため、TroveのDashboardおよびCLI(openstackコマンドなど) から操作します。
ここでは、K2HDKC DBaaS でK2HDKCクラスターの作成、スケール、削除について、また自動化されたK2HDKCスレーブの起動・確認方法について説明します。
以下の説明は、Trove Dashboard経由での操作説明になります。
CLI(openstackコマンドなど)の使い方については、Openstackのドキュメントなどを参照してください。
本章で説明する使い方は、K2HDKC DBaaS のK2HDKC DBaaS with Trove 環境を構築して、確認できます。
以降の説明は、以下の順序で説明します。
- K2HDKC DBaaS with Trove 環境構築
- Dashboardへのアクセスとログイン
- プロジェクトの選択
- K2HDKCクラスター情報(Configuration Group)
- K2HDKCクラスター構築(2通りの構築方法)
- K2HDKCスレーブノード(起動と確認)
1. K2HDKC DBaaS with Trove 環境構築
K2HDKC DBaaS with Troveを試すには、Trove(Trove is Database as a Service for OpenStack)の環境が必要となります。
簡単に試用環境を作成する方法については、K2HDKC DBaaS with Trove 環境構築で説明します。
2. Dashboardへのアクセスとログイン
まず、TroveのDashboardへアクセスします。
試用環境をお使いの場合、Dashboardへアクセスするには、K2HDKC DBaaSを構築したホストへアクセス(http://<hostname or ip address>)してください。

ログインが促されますので、利用するユーザのクレデンシャル(ユーザ名、パスフレーズ)でログインしてください。
試用環境を利用している場合は、ユーザ名:demoでログインします。
試用環境のdemoユーザのパスフレーズは、~/devstack/local.confファイルのADMIN_PASSWORD変数に登録されています。
ログインできたら、以下のような画面になります。
2-1. K2HR3システムへのログイン
K2HDKC DBaaS は、バックエンドでK2HR3システムを利用しています。
K2HDKC DBaaS で利用するK2HR3システムにアクセスできるか確認をしてください。
試用環境をお使いの場合、K2HR3システムへアクセスするには、K2HDKC DBaaSを構築したホストからアクセス(http://<hostname or ip address>:28080/)できます。
K2HDKCクラスターを起動・管理するために、K2HR3システムにアクセスする必要はありません。自動的なK2HDKCスレーブノードを起動するときにアクセスします。
K2HR3システムへのログインは、Trove Dashboardへログインするクレデンシャル(ユーザ名、パスフレーズ)と同じです。

3. プロジェクトの選択
Dashboardにログインしたら、K2HDKCクラスターを管理するプロジェクトを選択してください。
試用環境を利用している場合は、プロジェクト名:demoを選択してください。

4. K2HDKCクラスター情報(Configuration Group)
K2HDKC DBaaS でK2HDKCクラスターを構成するときに、クラスターの設定を与えるために必要となるConfiguration Groupを作成します。
以下の手順で作成してください。
4-1. Configuration Groupの作成
DashboardのDatabase > Configuration Groupsを選択してください。
+Create Configuration Groupボタンをクリックし、Create Configuration Groupダイアログを表示します。
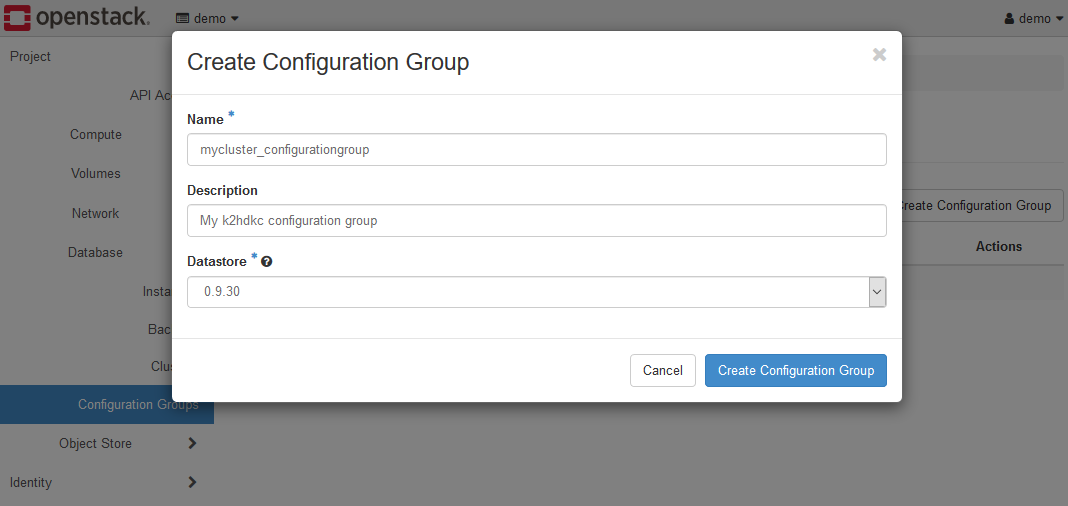
この例では、Name:mycluster_configurationgroupとしています。
Create Configuration Groupボタンをクリックして、Configuration Groupを作成してください。
4-2. Configuration Groupの設定
作成されたConfiguration Group:mycluster_configurationgroupが表示されますので、詳細を設定していきます。
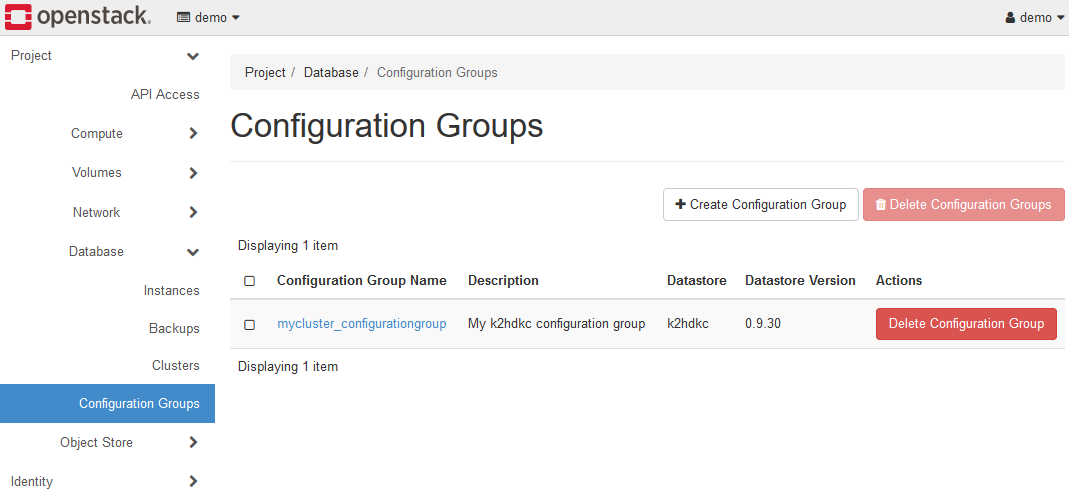
リンクをクリックすると、このConfiguration Groupのパラメータの設定画面に移動します。
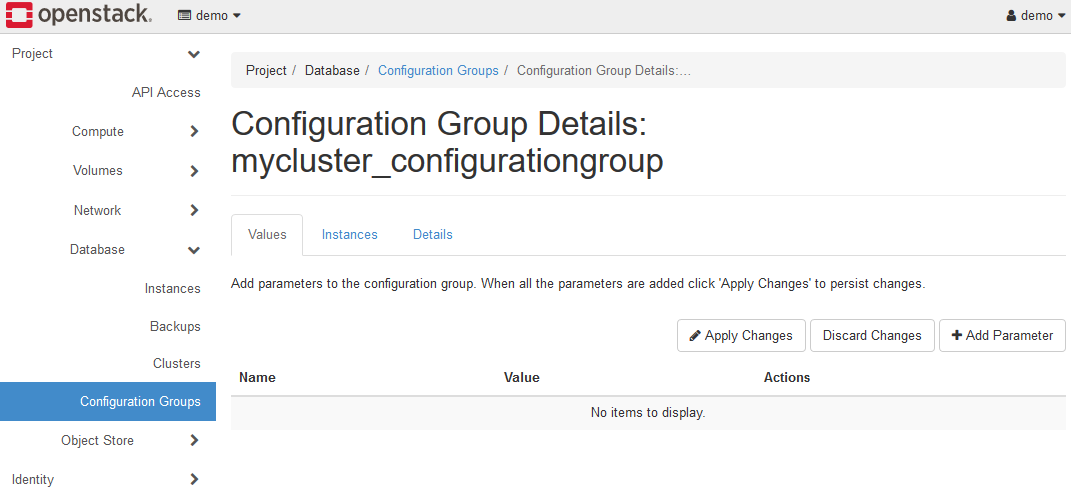
+Add Parameterボタンをクリックして、Add Parameterダイアログを表示します。
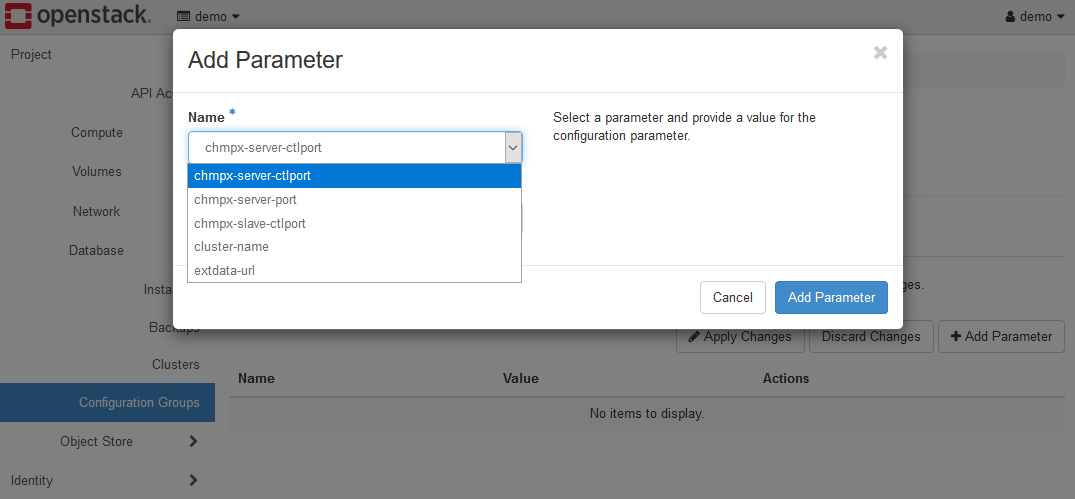
K2HDKC DBaaS で設定する最低限のパラメータは、cluster-name のみ です。
cluster-name パラメータ名を選択し、値を設定してください。
この例では、myclusterとしています。
extdata-urlは設定しないでください。この値は自動的に設定されます。
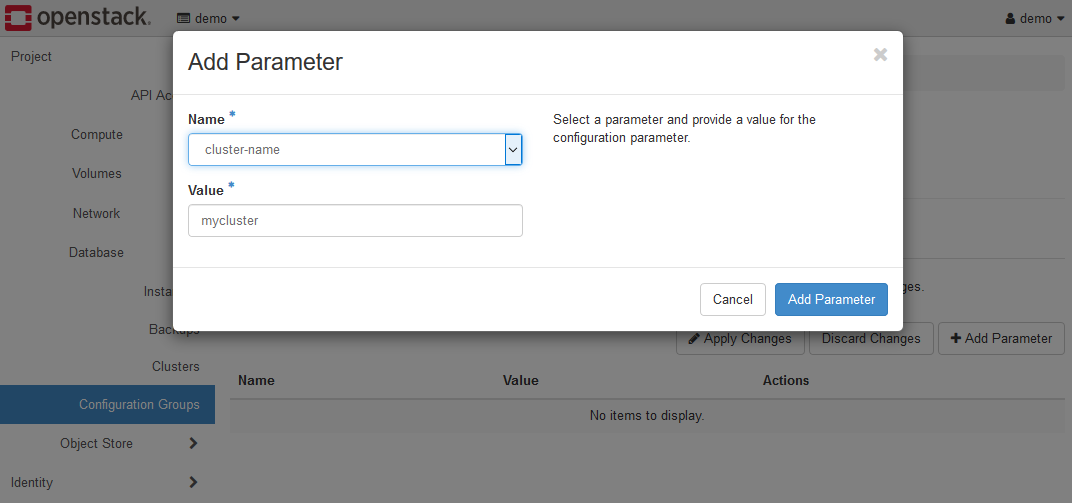
以下は、cluster-name パラメータを設定した直後の画面イメージです。
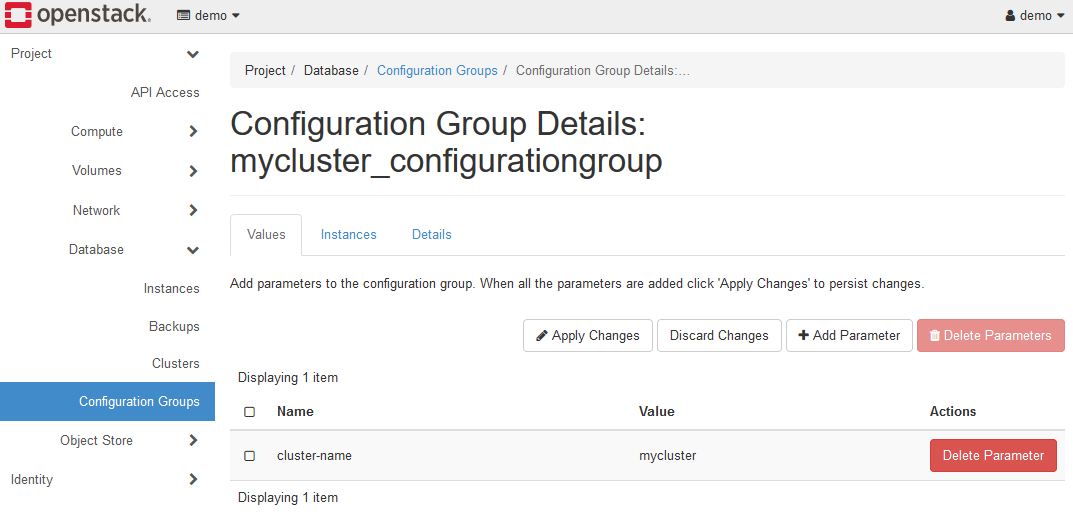
最後に、Apply Changesボタンをクリックして、設定を反映させます。
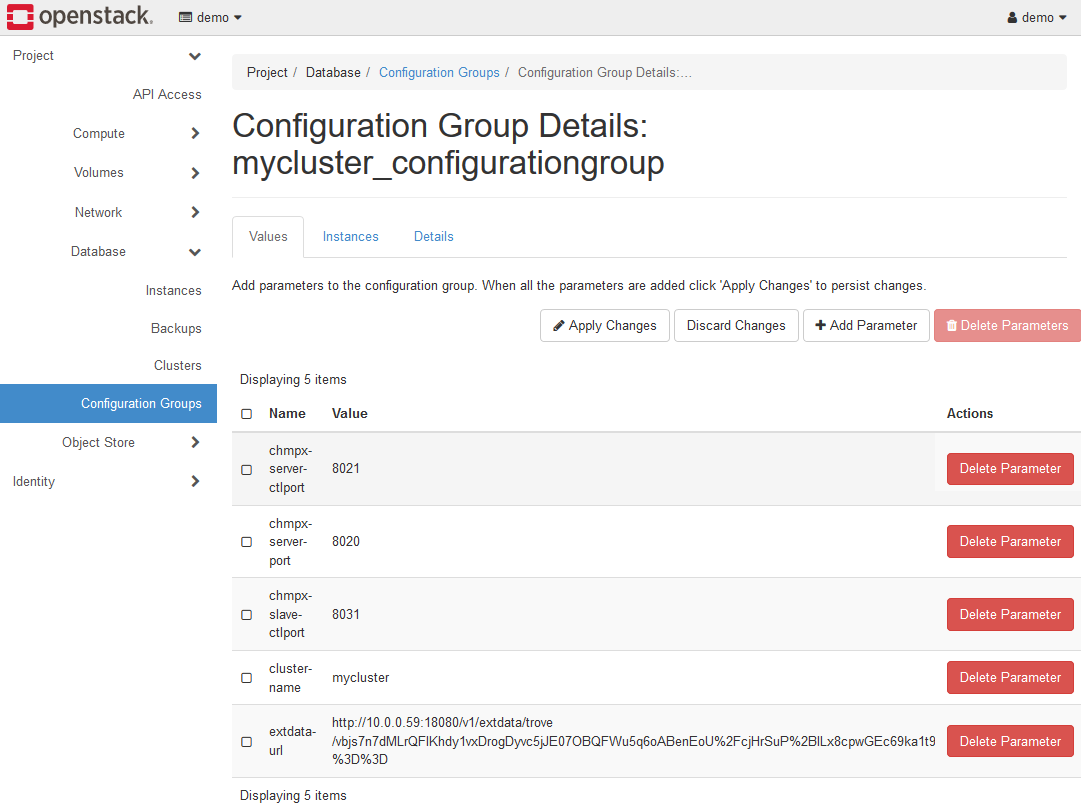
設定を反映させると、未指定だったパラメータもすべて自動的に補完されます。
特に理由がなければ、cluster-name パラメータのみの設定で十分です。
ここまでで、K2HDKCクラスター情報(Configuration Group)の設定が完了しました。
5. K2HDKCクラスター構築
K2HDKCクラスターの構築には、K2HDKC DBaaS は2通りの方法 を提供しています。
ひとつは、クラスター名、サーバーノード数を指定して、クラスターを構築し、クラスターの拡張・縮小・削除ができます。
もう一つは、クラスターのサーバーノードを個別に起動し、クラスターを構築する方法です。
後者の場合は、バックアップおよびバックアップしたデータからサーバーノードの起動(リストア)ができます。
基本的に、K2HDKCクラスターは、内部でサーバーノードが互いのデータを保持し、多重化されているため、バックアップおよびリストアの操作は不要です。
都度クラスターの縮小・拡張でこの操作を代用できます。
K2HDKC DBaaS では、データの多重化(サーバノードの多重化)を十分に行うことで、前者のクラスターの構築方法で安全に運用できます。
5-1. K2HDKCクラスターの一括構築と操作
ここでは、前者のK2HDKCクラスターを一括で構築する手順を説明します。
まず、Database > Clusters を開きます。
Launch Clusterボタンをクリックして、Launch Clusterダイアログを表示し、各項目を設定してください。
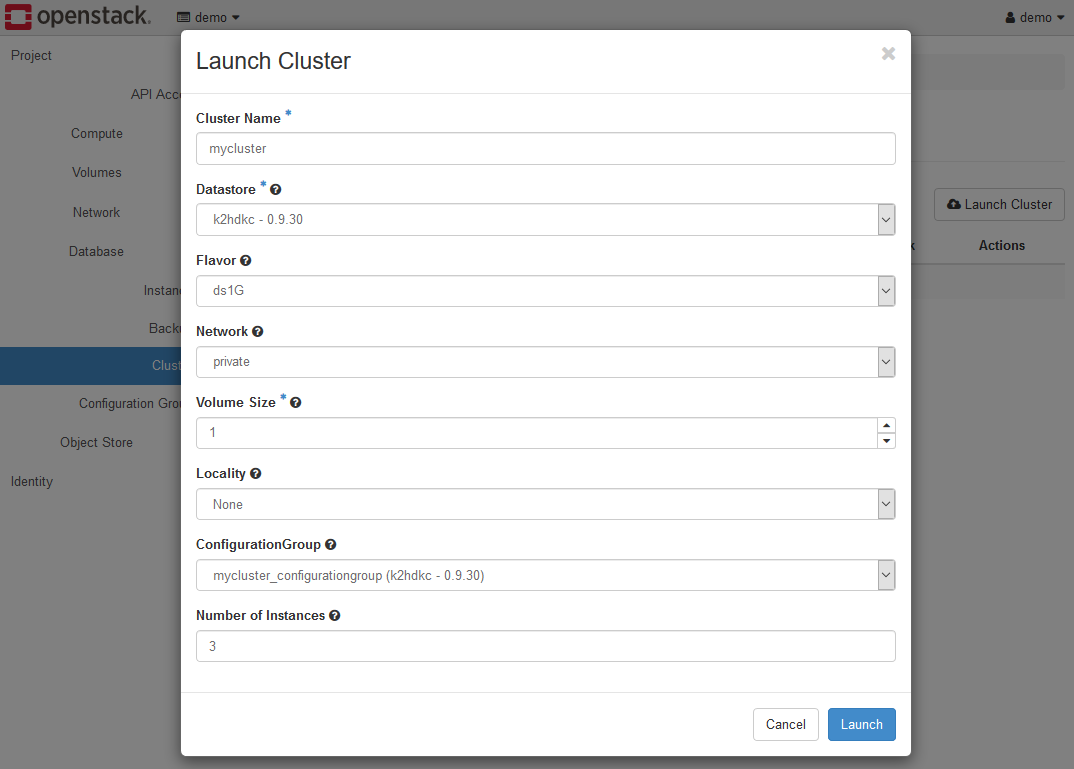
各項目は以下のように設定します。
- Cluster Name
この値は、K2HDKCクラスターのサーバーノードのHOST(Virtual Machine)の名前の一部分になります。上図では、myclusterとしています。 - Datastore
k2hdkc - 1.0.14などのように K2HDKCのバージョンが一覧されますので、存在するものを選択してください。 - Flavor
フレーバーを選択します。試用環境を使用している場合は、ds2Gを選択してください。 - Network
試用環境を使用している場合は、privateを選択します。 - Volume Size
試用環境を使用している場合は、2としてください。 - Locality
試用環境を使用している場合は、Noneを選択します。 - ConfigurationGroup
上記で作成したConfiguration Groupがリストされていますので、選択してください。ここまで手順通りに進めている場合、mycluster_configurationgroup (k2hdkc-1.0.14)を選択します。 - Number of Instances
起動するK2HDKCクラスターのサーバノード数を指定します。デフォルトは3となっています。
上記の設定で、Launchボタンをクリックすると、K2HDKCクラスターが起動します。
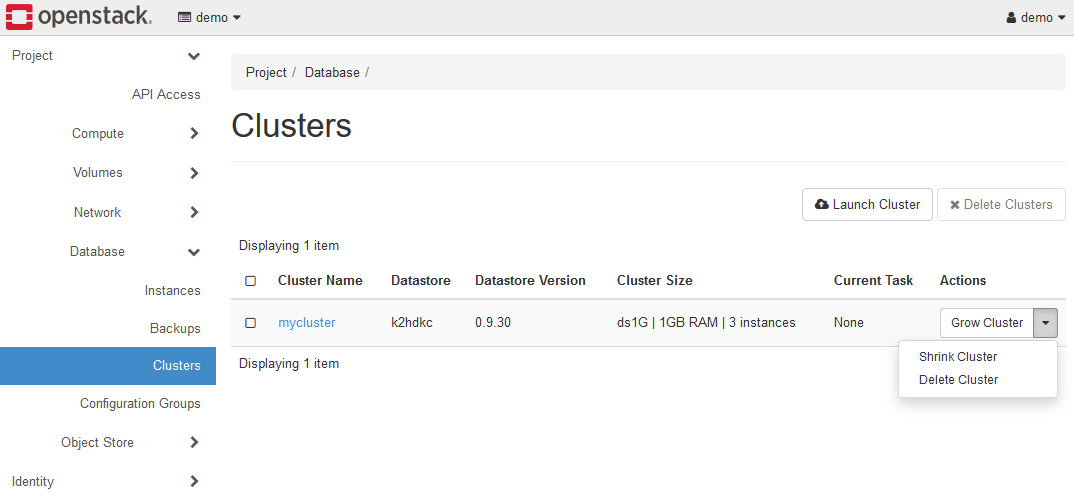
起動したクラスターのメニューから、クラスターの拡張(Grow Cluster)、縮小(Shrink Cluster)、削除(Delete Cluster)が実行できます。
5-1-1. K2HDKCクラスターの状態
上述のCluster Nameのリンク(上図ではmycluster)をクリックすると、K2HDKCクラスターのサーバーノードの状態を確認できます。
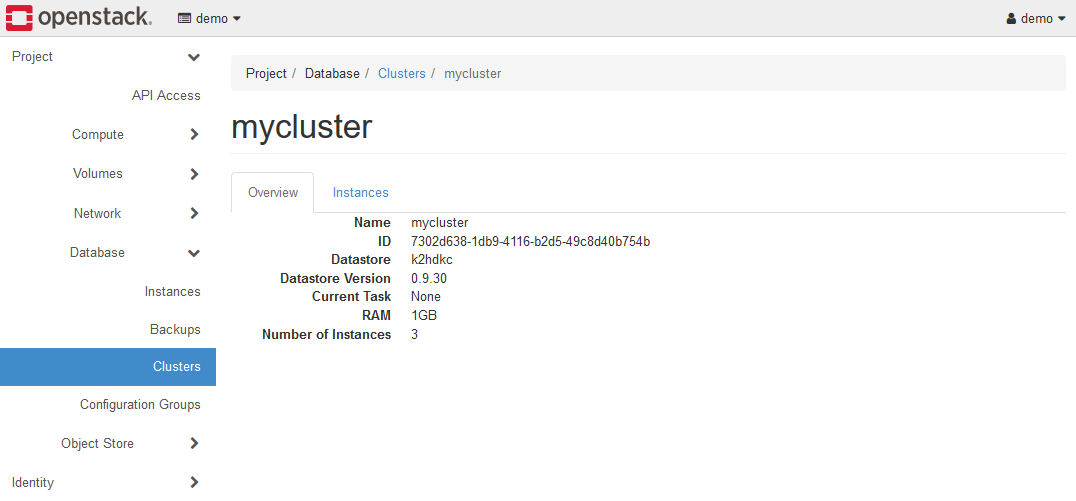
Instancesタブを開くと、K2HDKCクラスターを構成するサーバノードの情報を表示できます。
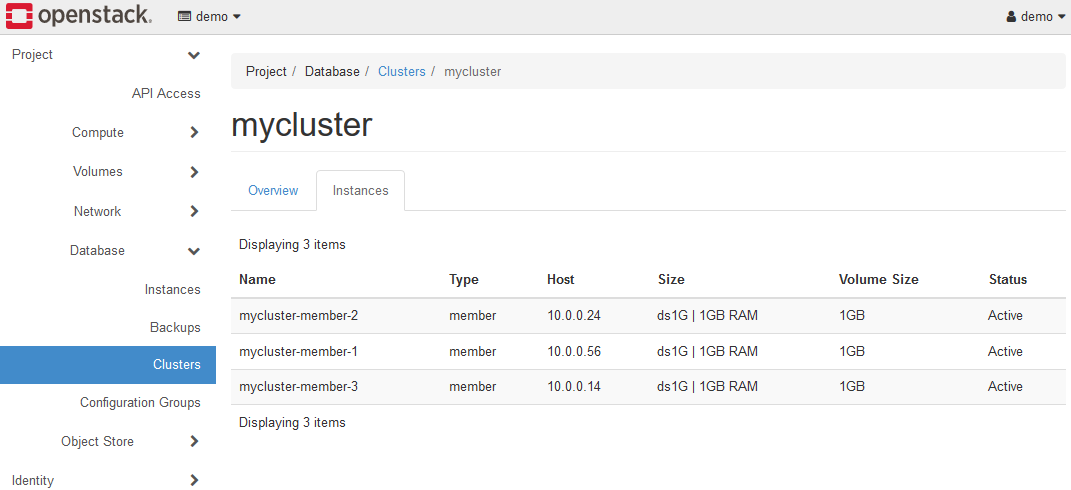
5-1-2. K2HDKCクラスターの拡張
クラスターの拡張(Grow Cluster)メニューを選択し、K2HDKCクラスターを拡張(サーバーノードの追加)できます。
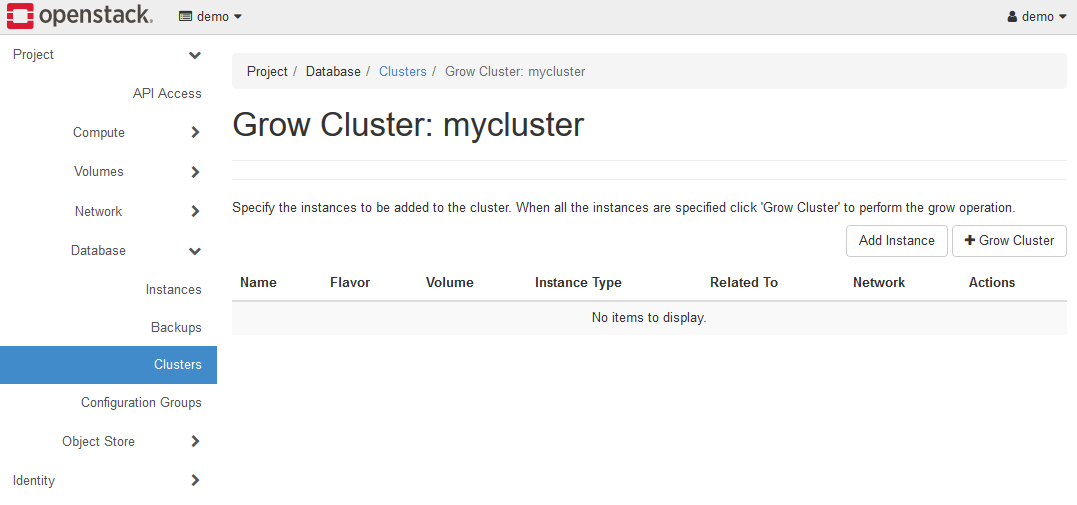
上記のAdd Instanceボタンをクリックし、Add Instanceダイアログを表示し、各項目を設定します。
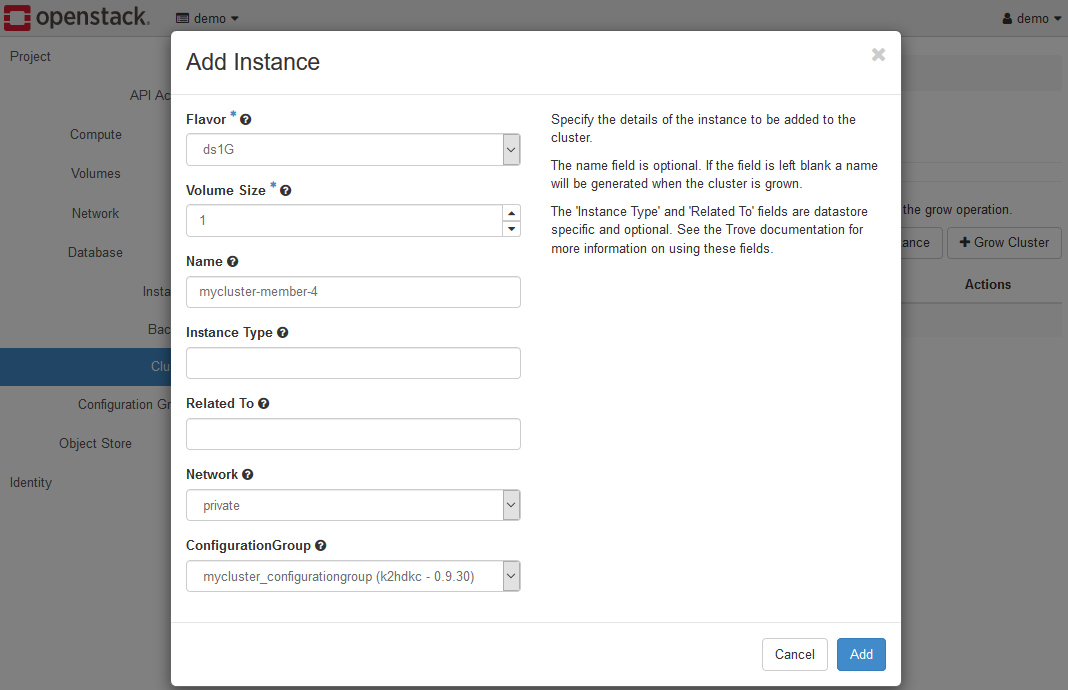
各項目は以下のように設定します。
- Flavor
フレーバーを選択します。他のサーバーノードと同じものを選択するようにします。 - Volume Size
他のサーバーノードと同じものを選択するようにします。試用環境を使用している場合は、2としてください。 - Name
この値は、追加するサーバーノードのHOST(Virtual Machine)の名前になります。上図では、既存サーバーノードと合わせてmycluster-member-4としています。 - Instance Type / Related To
これらの値は入力する必要はありません。 - Network
他のサーバーノードと同じものを選択するようにします。試用環境を使用している場合は、privateを選択します。 - ConfigurationGroup
他のサーバーノードと同じものを選択するようにします。ここまで手順通りの場合は、mycluster_configurationgroup (k2hdkc-1.0.14)を選択します。
上記の設定で、Addボタンをクリックしてください。
複数のサーバーノードを同時に追加する場合には、このAdd Instanceの作業を追加分繰り返してください。
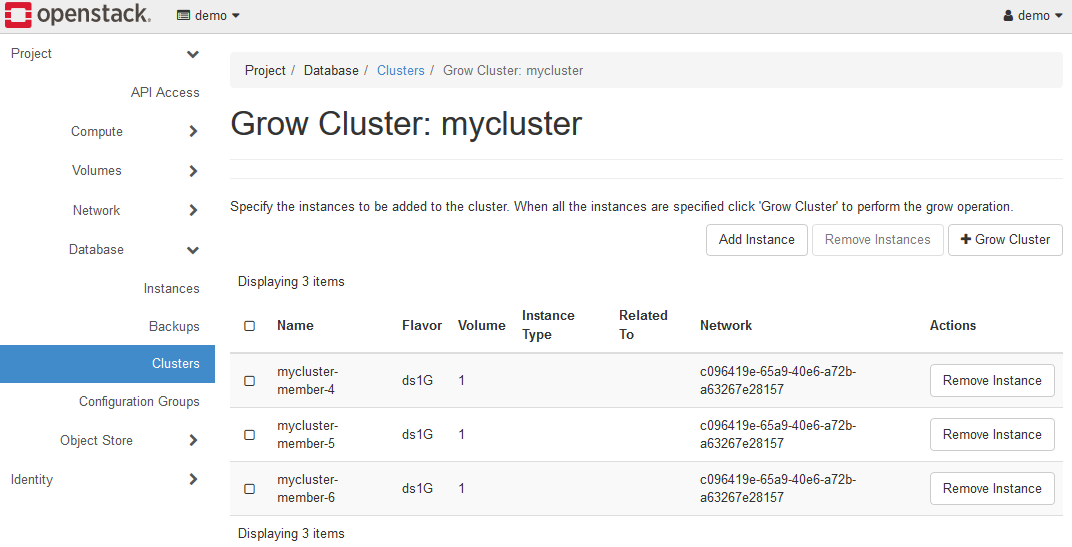
作業を完了すると、上図のようになります。
この時点では、まだK2HDKCクラスターの拡張はされていません。
つまり、拡張予定のサーバーノードの情報を準備した状態です。
この画面にて、+Grow Clusterボタンをクリックすることで、K2HDKCクラスターが拡張(サーバーノードの追加)されます。
サーバーノードが追加された場合、K2HDKCクラスターは内部データの再配置を自動的に行います。(オートデータマージ)
また、K2HDKCクラスターの構成管理も自動的に行われます。(オートスケールアウト)
よって、ユーザはクラスターの拡張を指示するだけで、他の操作を行う必要はありません。
5-1-3. K2HDKCクラスターの縮小
クラスターの縮小(Shrink Cluster)メニューを選択し、K2HDKCクラスターを縮小(サーバーノードの削除)ができます。
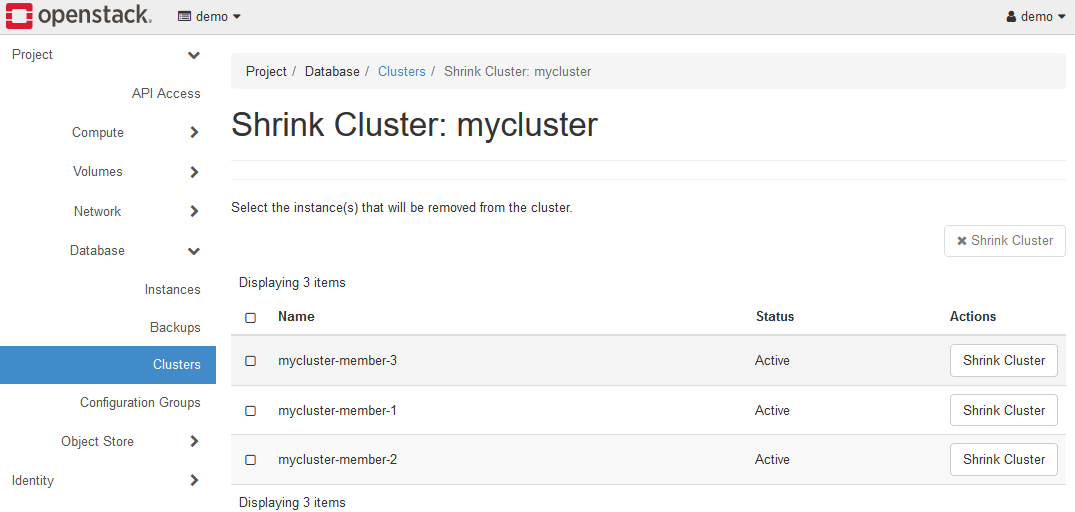
削除したいサーバーノードを選択し、Shrink Clusterボタンをクリックしてください。
サーバーノードが削除された場合、K2HDKCクラスターは内部データの再配置を自動的に行います。(オートデータマージ)
また、K2HDKCクラスターの構成管理も自動的に行われます。(オートスケールイン)
よって、ユーザはクラスターの縮小を指示するだけで、他の操作を行う必要はありません。
5-1-4. K2HDKCクラスターの削除
クラスターの削除(Delete Cluster)メニューを実行すると、K2HDKCクラスターが削除されます。
K2HDKCクラスターを構成するサーバーノードはすべて削除されます。
5-2. インスタンスからK2HDKCクラスター構築および操作
ここでは、K2HDKCクラスターをサーバーノードのインスタンスを個別に起動し、K2HDKCクラスターとして組み上げる手順を説明します。
まず、Database > Instances を開きます。
Launch Instanceボタンをクリックして、Launch Instanceダイアログを表示し、各項目を設定してください。
Launch Instanceダイアログを表示すると、いくつかのタブに分割されていますので、各タブ毎に説明します。
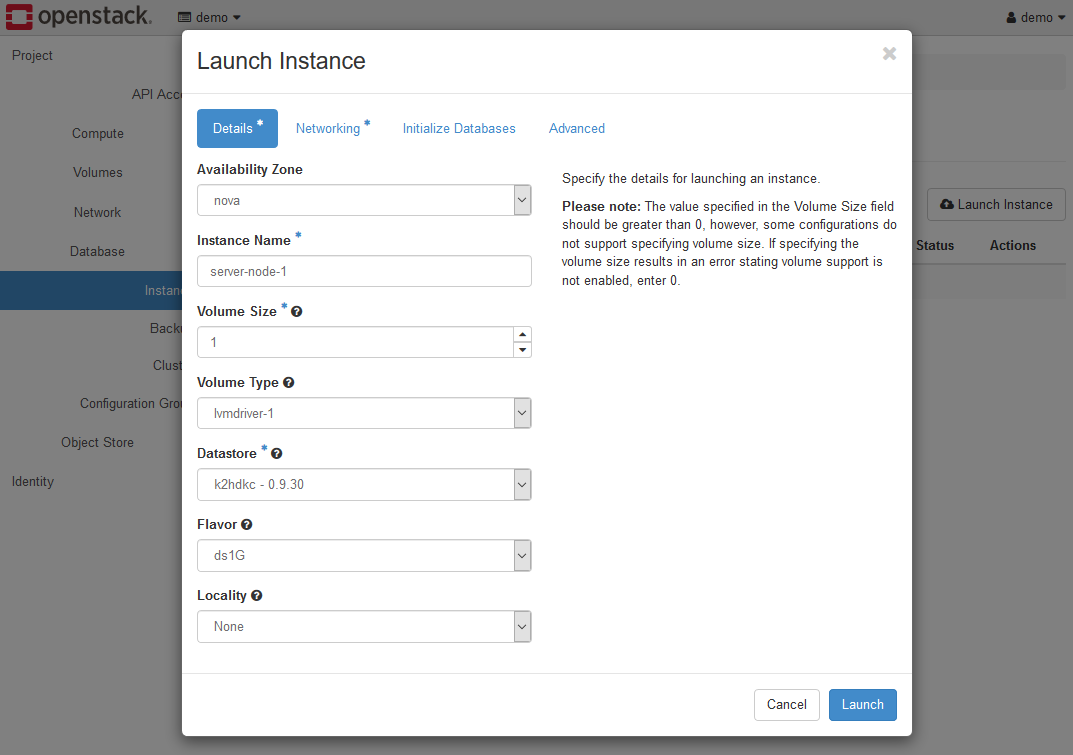
Detailsタブの各項目は以下のように設定します。
- Availability Zone
アベイラビリティゾーンを指定します。試用環境を使用している場合は、novaを選択します。 - Instance Nmame
サーバーノードのインスタンスの名称を指定します。この例では、server-node-1としています。 - Volume Size
試用環境を使用している場合は、2としてください。 - Volume Type
試用環境を使用している場合は、lvmdriver-1を選択してください。 - Datastore
k2hdkc - 1.0.14などのように K2HDKC バージョンが一覧されますので、存在するものを選択してください。 - Flavor
フレーバーを選択します。試用環境を使用している場合は、ds2Gを選択してください。 - Locality
試用環境を使用している場合は、Noneを選択します。
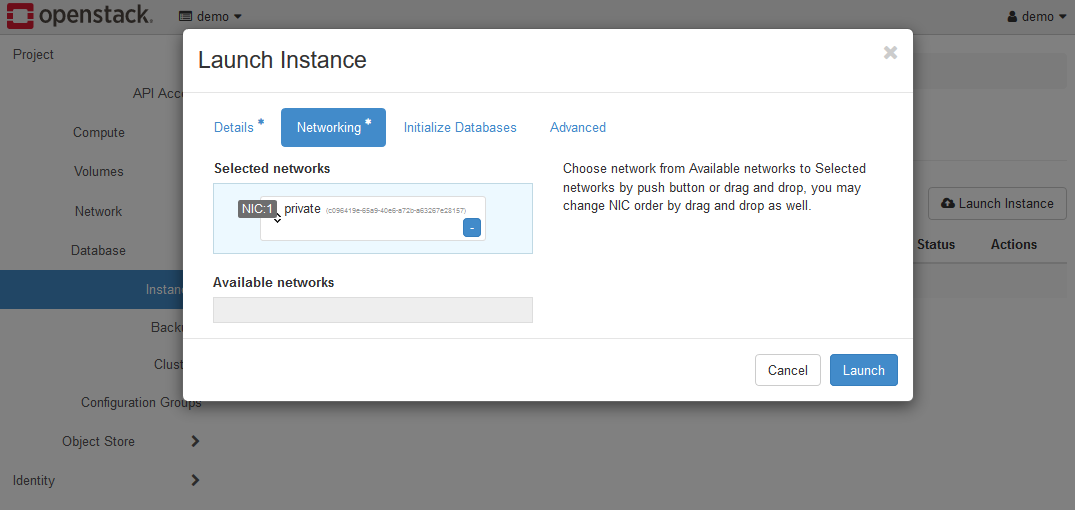
Networkingタブの各項目は以下のように設定します。
- Selected Networks
privateが選択されている状態です。試用環境を使用している場合は、このままとします。
Initializing Databasesタブの各項目は、未設定のままにしてください。
特に設定する必要な項目はありません。
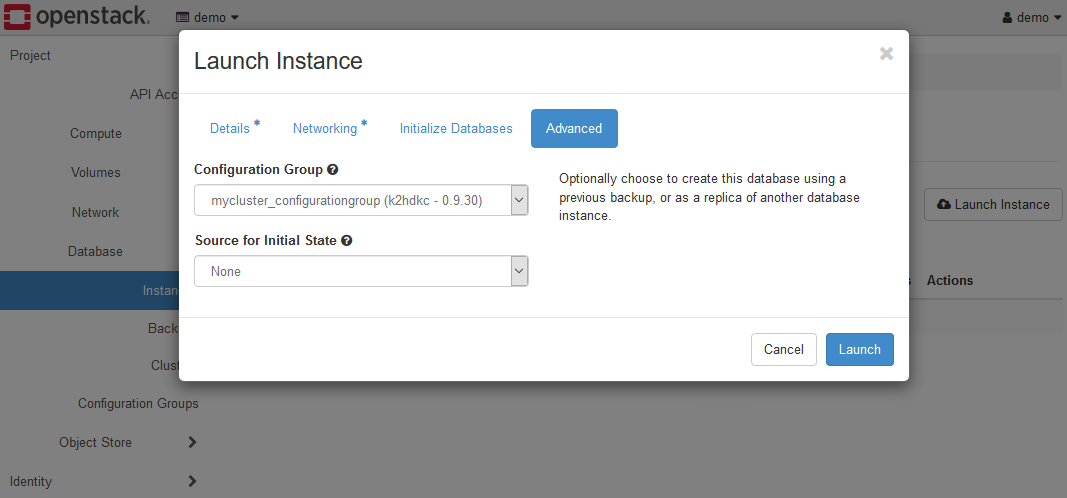
Advancedタブの各項目は以下のように設定します。
- ConfigurationGroup
手順通りの場合は、mycluster_configurationgroup (k2hdkc-1.0.14)を選択します。 - Source for initial state
Noneのままとします。
上記の設定で、Launchボタンをクリックすると、K2HDKCクラスター用のサーバーノードが1つ起動します。
このように1つのサーバーノードが起動したら、K2HDKCクラスターに必要なサーバーノードを順次起動します。
最終的に、3つのサーバーノードを起動した場合、以下の図のように表示されます。
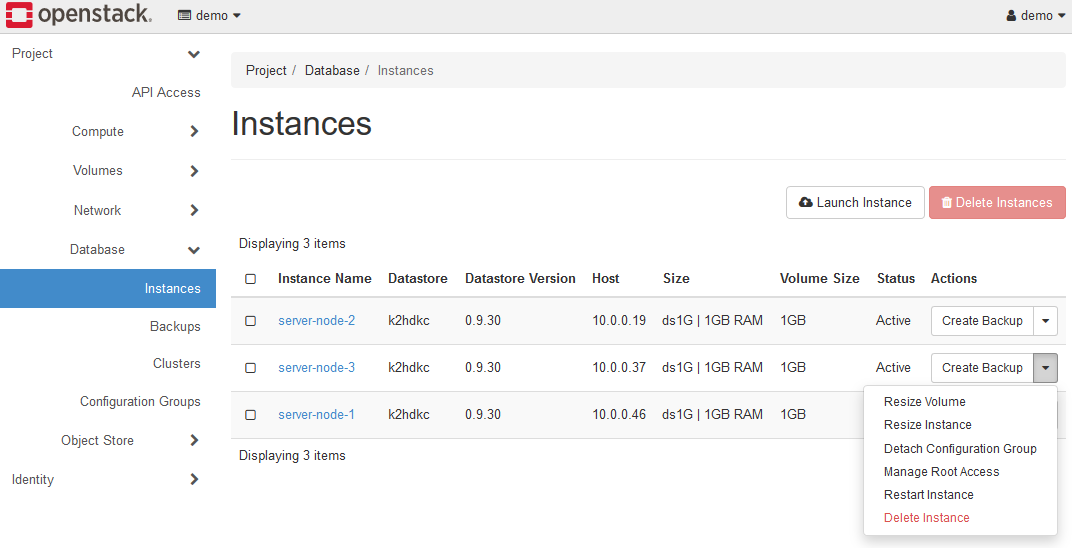
この状態は、3つのサーバーノードで構成されたK2HDKCクラスターを構築したことになります。
この手順は、サーバーノードを順次起動し、K2HDKCクラスターの拡張を行いつつ、クラスターを構成できます。
サーバーノードは順次追加されますが、K2HDKCクラスターは内部データの再配置を自動的に行いますので、データ操作は不要です。(オートデータマージ)
また、自動的にK2HDKCクラスターの構成管理も行われます。(オートスケールアウト)
上図Instancesの各インスタンスにあるメニューDetach Configuration Groupを使い、インスタンスを起動したままK2HDKCクラスターからサーバーノードの登録を解除し、K2HDKCクラスターの縮小ができます。
また、Delete Instanceメニュー(もしくはボタン)は、そのインスタンスを削除(サーバーノードを削除)し、K2HDKCクラスターの縮小をします。
Create backupメニューは、そのインスタンス(サーバーノード)の持つK2HDKCデータのバックアップを作成します。
これらの説明は後述します。
なお、Resize Volume、Resize Instance、Manage Root Access、Restart Instanceメニューは、K2HDKC DBaaSでは使いません。
5-2-1. インスタンスの情報
インスタンス一覧の画面から、Instance Nameをクリックすると、インスタンスの情報を表示できます。
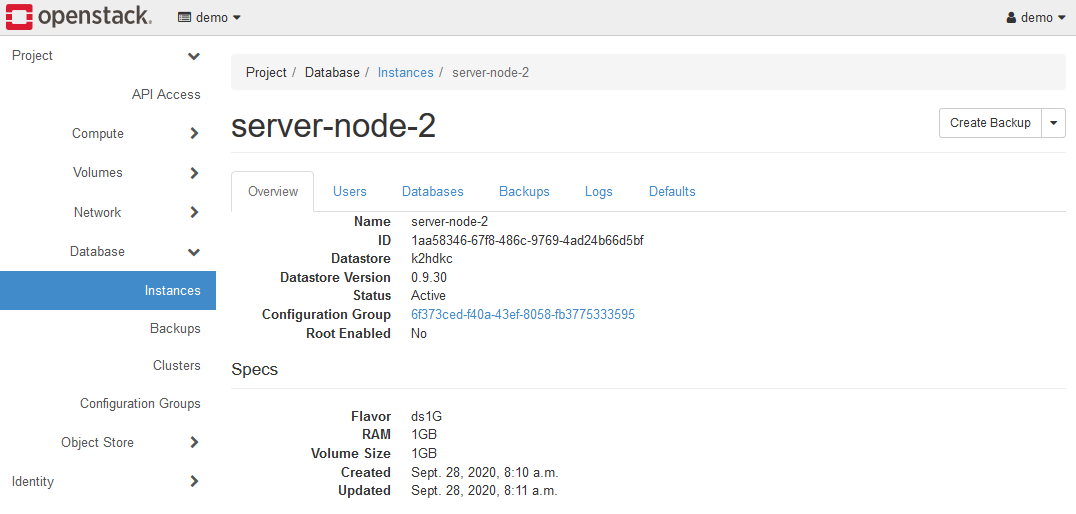
K2HDKC DBaaS では、Overviewのみ機能します。
その他のタブは、分散KVSであるK2HDKCには不要な情報であり、機能しないようになっています。
Overviewには、Configuration GroupのIDが表示されています。
インスタンスから構築されたサーバーノードが属するK2HDKCのクラスターを判別するには、Configuration Groupの値を確認してください。
5-2-2. インスタンスをK2HDKCクラスターから削除
インスタンスをK2HDKCクラスターから削除(K2HDKCクラスターの縮小)を行う場合、Detach Configuration Groupメニューを使います。
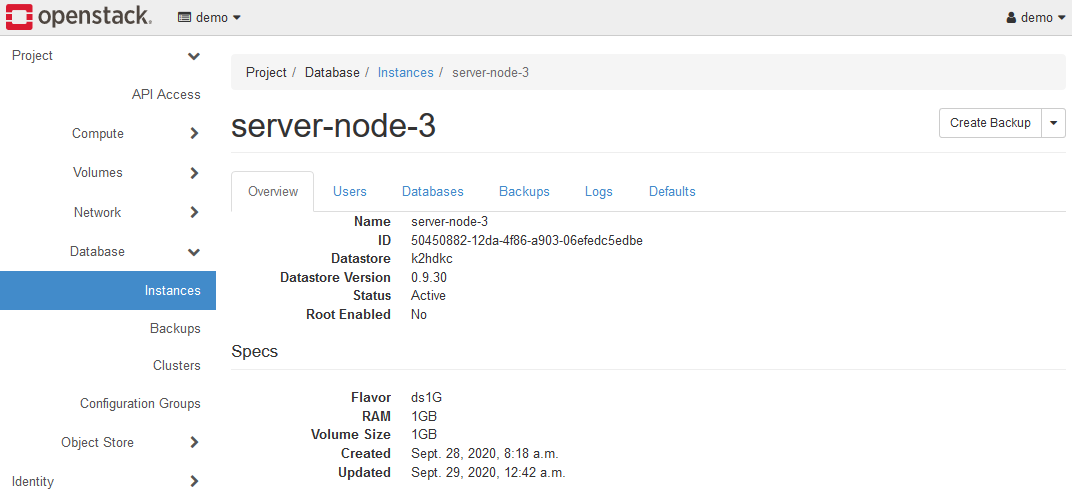
K2HDKCクラスターから削除(Configuration Groupの解除)を実行したインスタンスは、上記のような状態となります。
K2HDKCクラスターに組み込まれた(Configuration Groupを設定)インスタンスと異なり、Configuration GroupのIDが存在しなくなります。
この状態のインスタンスは、K2HDKCのサーバーノードとして起動はしていますが、どのK2HDKCクラスターにも属していない状態です。
この状態の場合、インスタンス一覧のメニュー項目が以下のようになっています。
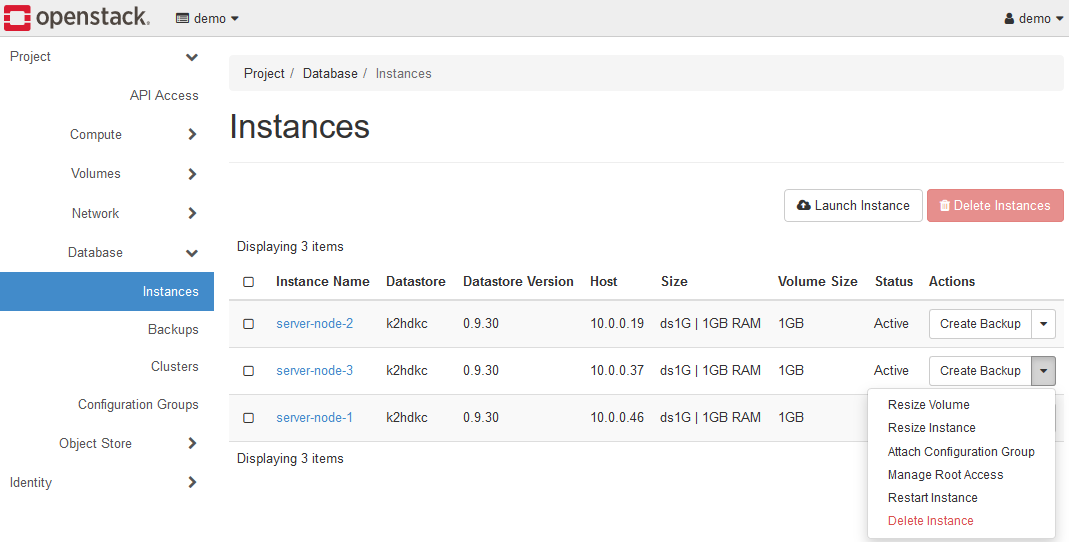
メニューは、Detach Configuration Groupがなくなり、Attach Configuration Groupに切り替わります。
5-2-3. インスタンスをK2HDKCクラスターに追加
前述のように、K2HDKCクラスターに属していないインスタンスをK2HDKCクラスターに追加することができます。
この操作により、K2HDKCクラスターの拡張ができます。
Attach Configuration Groupメニューを選択すると、Attach Configuration Groupダイアログが開きます。
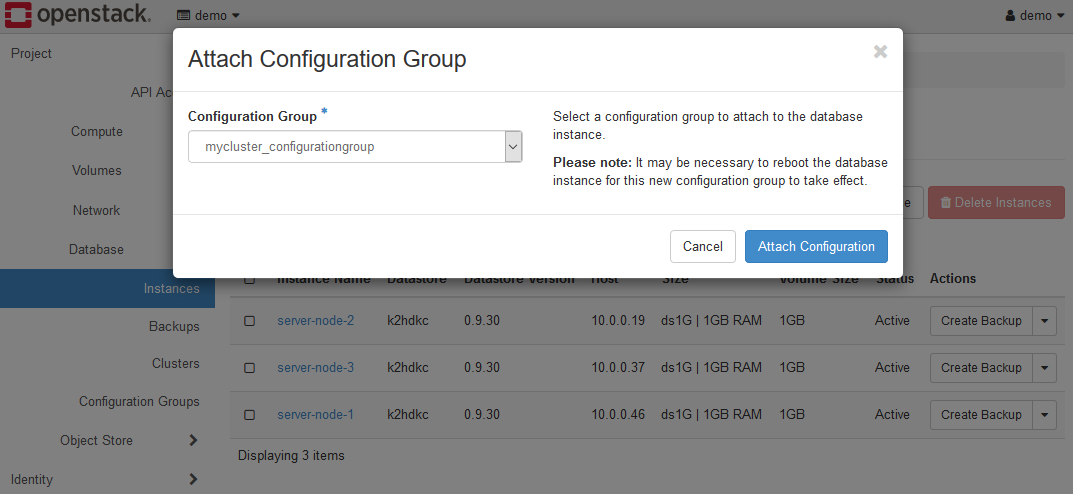
Configuration Group項目の値に、拡張したいK2HDKCクラスターで使用しているConfiguration Groupを選択してください。
Attach Configuration Groupボタンをクリックすると、このインスタンスはK2HDKCクラスターに追加されます。
5-2-4. バックアップ
K2HDKCクラスターに属したインスタンスのバックアップを作成することができます。
バックアップをとるインスタンスのCreate Backupメニューを選択してください。
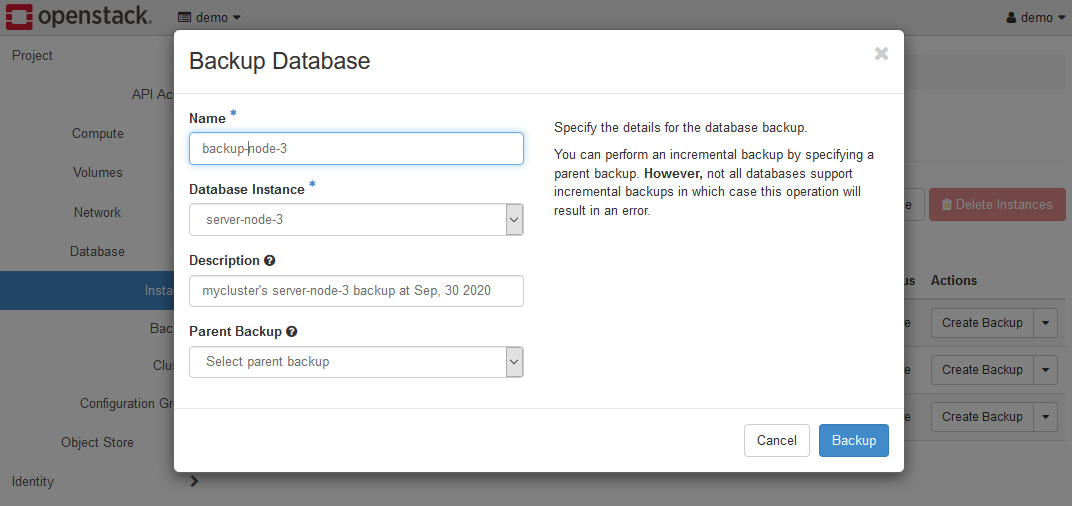
Backup Databaseダイアログが表示されますので、各項目を設定してください。
- Name
バックアップデータを区別する名前です。 - Database Instance
バックアップするインスタンスを選択してください。 - Description
バックアップデータに付与する付属情報を入力します。 - Parent Backup
K2HDKC DBaaS では差分バックアップをサポートしていないので、未選択のままとしてください。
設定が完了したら、Backupボタンをクリックします。
バックアップが正常に作成されると、Database > Backups パネルに移動します。
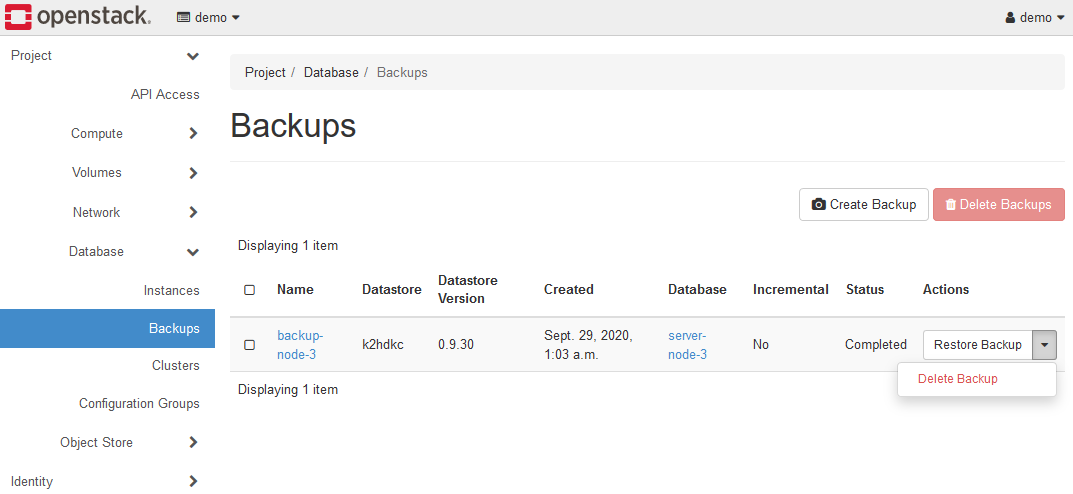
バックアップデータのリストが表示されます。
この画面には、各バックアップにDelete BackupとRestore Backupのメニューがあります。
また、バックアップをしたデータのNameをクリックすると、バックアップデータの詳細が表示されます。
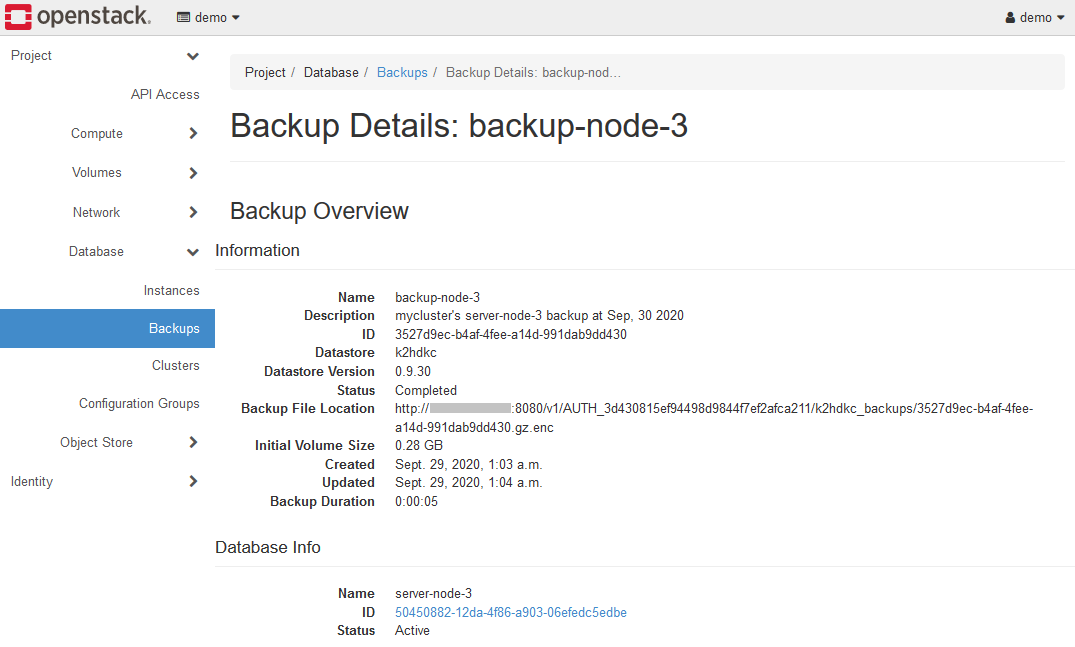
インスタンスのバックアップデータは、K2HDKC DBaaS が動作しているOpenStackコンポーネントのObject Storeに保存されています。
Object Store > Containersを開き、k2hdkc backupsコンテナーを選択してください。
K2HDKC DBaaSの連携しているOpenStack環境により異なる場合があります。
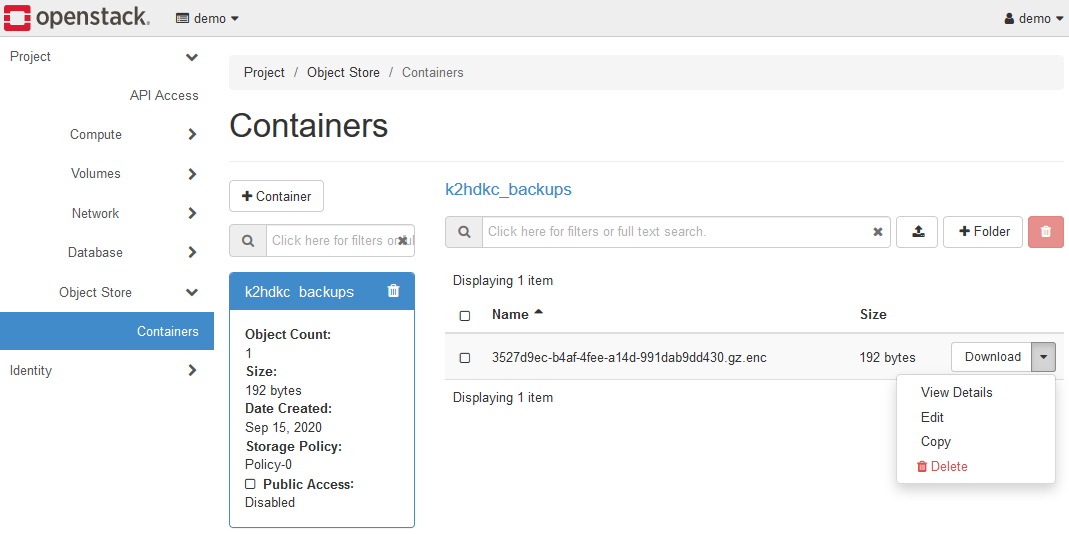
作成したバックアップのファイル(.gz.encファイル)がリストされています。
このように、K2HDKC DBaaS で作成したバックアップは、Object Storeに保存されています。
Object Storeの使い方などについては、OpenStackのドキュメントを参照してください。
Swiftのドキュメントが参考になります。
5-2-5. リストア
Database > Backups の画面に表示されているバックアップデータのRestore Backupメニューから、バックアップデータを指定してインスタンスを起動できます。
インスタンスを構成し、初期データとしてバックアップデータをリストアした状態で、そのインスタンスを起動できます。
リストアを実行すると、Launch Instanceダイアログが表示します。
このリストア操作のインスタンス起動のためのダイアログは、上述したインスタンスの起動とAdvancedタブを除き、同じです。
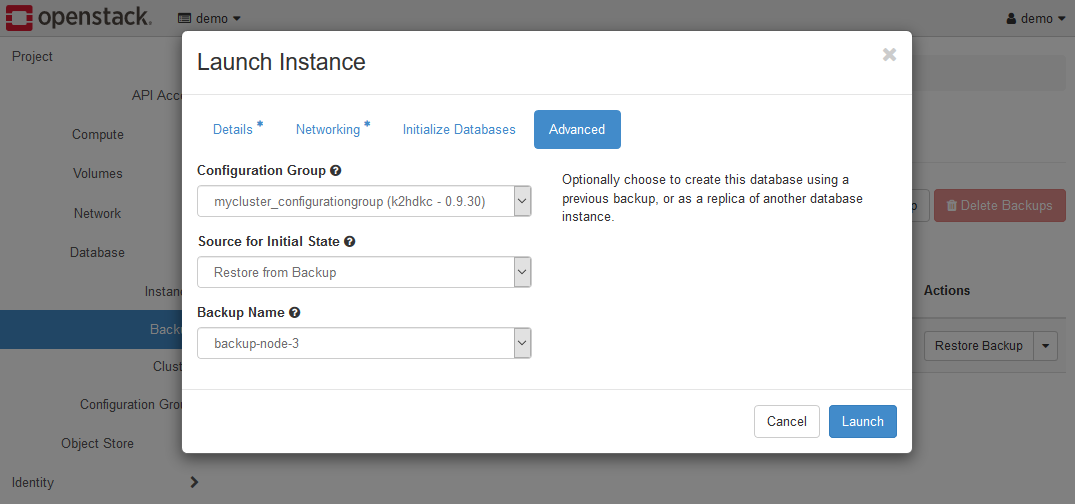
上記は、Launch InstanceダイアログのAdvancedタブです。
Advancedタブの各項目は以下のように設定します。
- ConfigurationGroup
起動するインスタンスが属するK2HDKCクラスターと同じConfiguration Groupを選択してください。 - Source for initial state
Restore from Backupとします。 - Backup Name
バックアップデータを選択してください。
Details、Networking、Initialize Databasesのタブは、インスタンスの起動時と同様に設定してください。
すべて設定後、Launchボタンをクリックすると、バックアップデータをリストアした状態でインスタンスが起動します。
6. K2HDKCスレーブノード
K2HDKC DBaaS で構築したK2HDKCクラスターにアクセスするK2HDKCスレーブノードについて説明します。
K2HDKCスレーブノードは、K2HDKCがサポートするOSで動作させてください。
K2HDKC DBaaS の機能を使うと、K2HDKCスレーブノードは、K2HDKCクラスターの構成に柔軟に対応できます。
例えば、K2HDKCクラスターの拡張・縮小が行われた場合、その変更を自動で検知し、自動的にK2HDKCスレーブノードの設定を更新できます。(オートコンフィグレーション)
K2HDKC DBaaS の機能を使ったK2HDKCスレーブノードの起動・操作を説明します。
6-1. K2HR3からUser Data Script取得
K2HDKC DBaaS を使ったK2HDKCスレーブノードを起動するには、バックエンドで動作しているK2HR3システムを使います。
ここでは、試用環境として構築されたK2HDKC DBaaSの環境を前提として説明します。
K2HDKC DBaaS の機能を使ったK2HDKCスレーブノードを起動ためには、User Data Scriptが必要となります。
以下の手順で、User Data ScriptをK2HR3システムから取り出します。
6-1-1. K2HR3ログイン
バックエンドで動作しているK2HR3システム にログインし、K2HDKCクラスターと同じプロジェクト(テナント)を選択してください。
試用環境を使っている場合は、ユーザ:demoでログインし、プロジェクト(テナント):demoを選択します。

上記は、プロジェクト(テナント)の選択直後です。
6-1-2. ROLEトークンの生成
次に、ROLEを選択し、K2HDKCクラスターと同じ名前のROLE名を選択し、その中にあるslaveを選択してください。
試用環境を使い、上記までの手順でK2HDKCクラスターを作成した場合には、ROLE > mycluster > slaveを選択します。
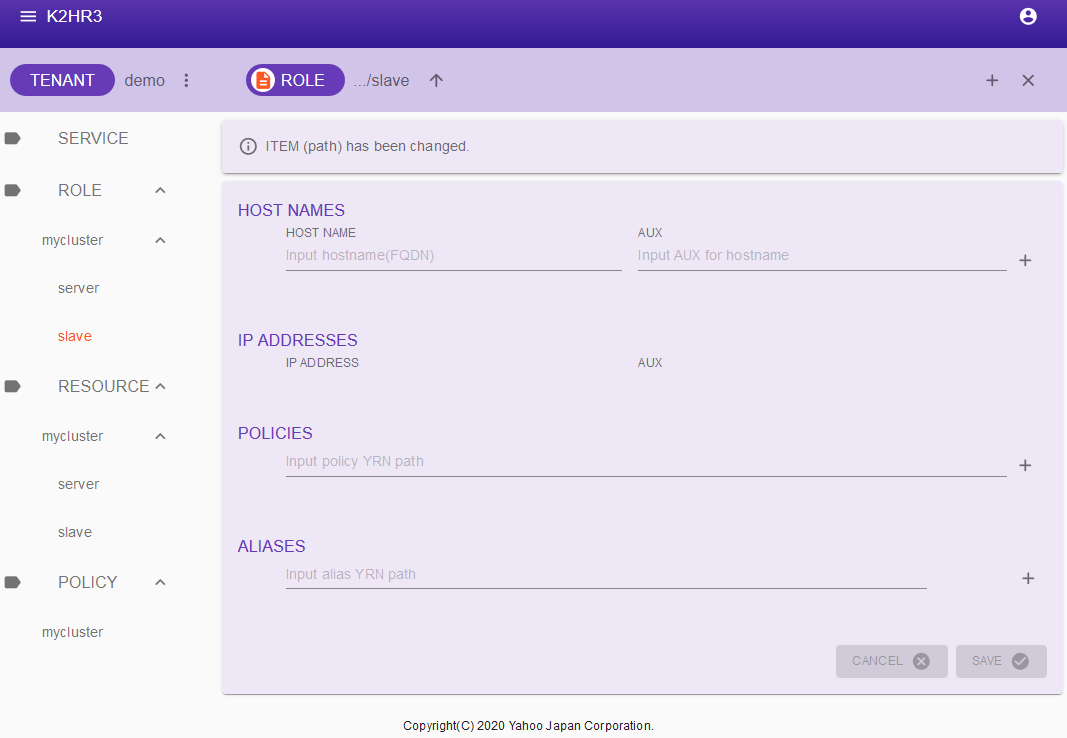
このROLEは、K2HDKCスレーブノード用のROLEになっています。
この画面で、上部のツールバーにあるROLEボタンをクリックします。
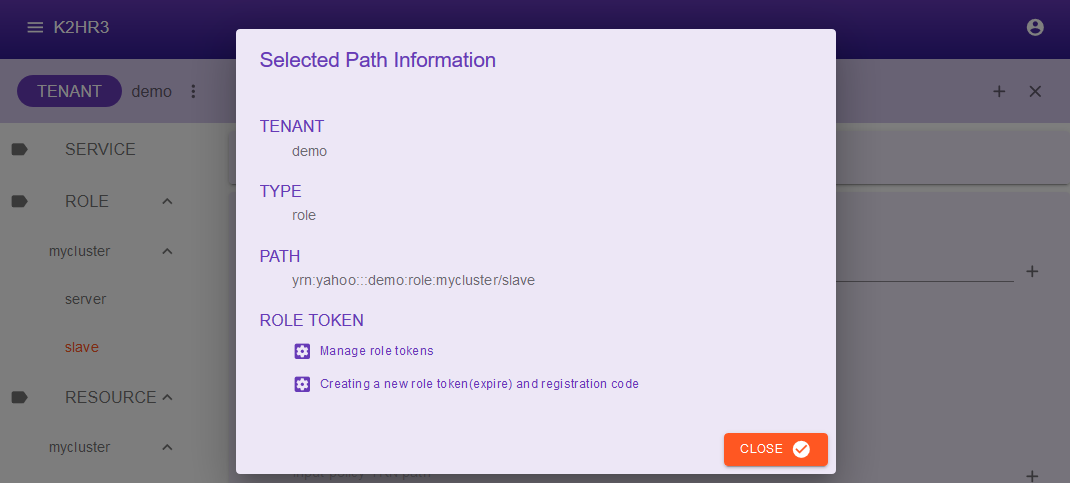
Selected Path Informationダイアログが表示されますので、Manage role tokensリンクをクリックしてください。
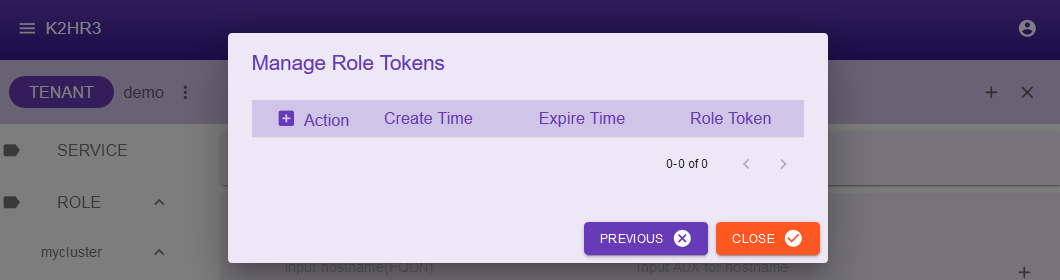
このダイアログは、K2HR3が選択したROLE(ROLE > mycluster > slave)用に発行したROLEトークンの一覧を表示しています。
新たにROLEトークンを発行します。
発行済みの場合は次の手順に進んでください。
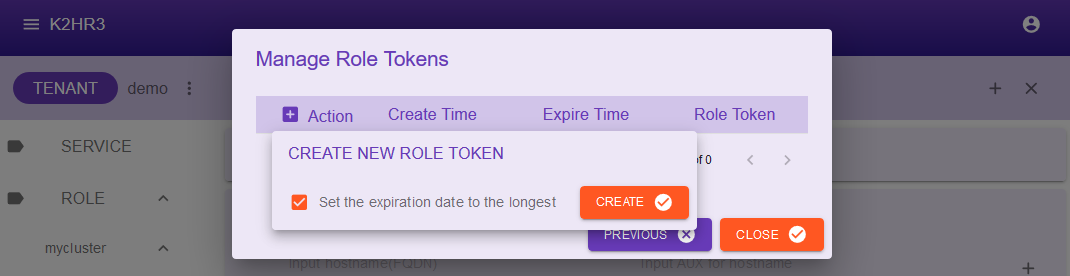
Action文字の横にある+ボタンをクリックすると、上記のCREATE NEW ROLE TOKENがポップアップします。
このポップアップダイアログの中の、Set the expiration date to the longestチェックボックスをチェックし、CREATEボタンをクリックしてください。
ROLEトークンの有効期限は、用途に応じて判断してください。
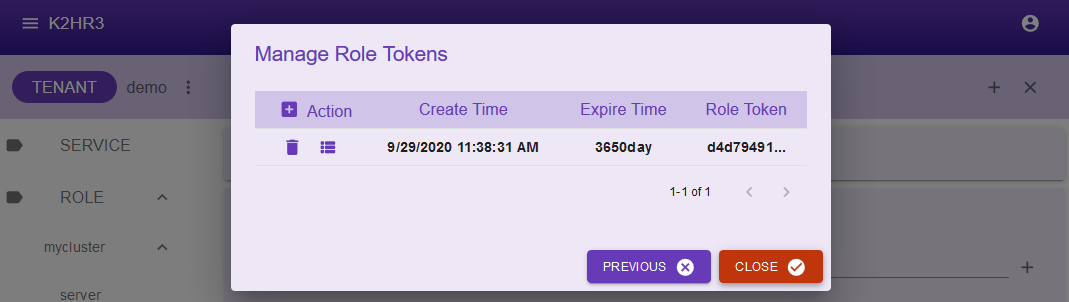
ROLEトークンが発行され、リストされます。
6-1-3. User Data Script取得
作成されたROLEトークン(もしくは既存のROLEトークン)のAction列にある2番目のボタンをクリックしてください。
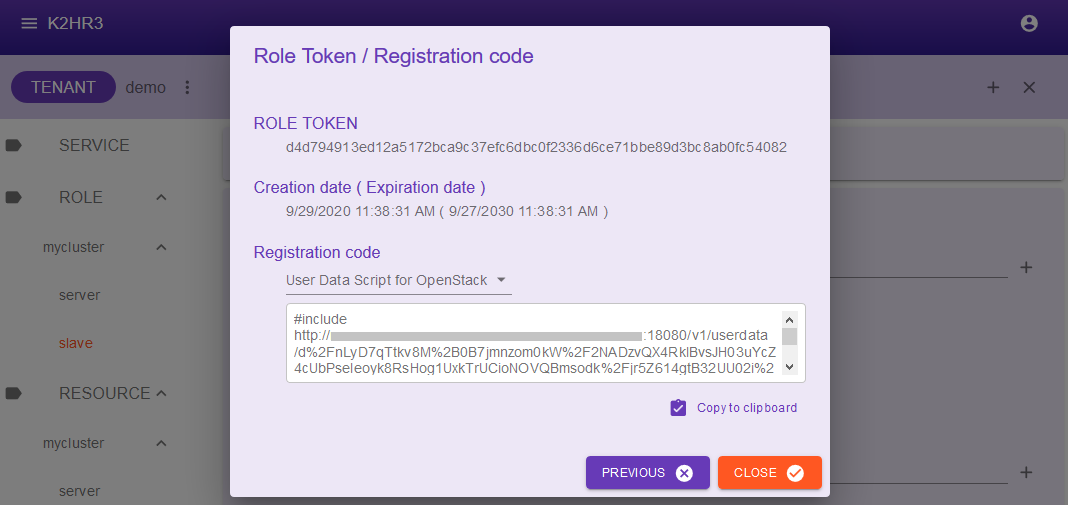
Role token/Registration codeダイアログが表示されます。
Registration codeプルダウンリストからUser Data Script for OpenStackを選択してください。
テキストボックスに、User Data Scriptの値が表示されますので、Copy to clip boardボタンなどを使い、内容をコピーしてください。
6-2. K2HDKCスレーブノードの起動
User Data Scriptを使い、K2HDKCスレーブノードを起動します。
K2HDKCスレーブノードの起動は、OpenStackの通常のインスタンスとして起動します。
K2HDKCスレーブノードは、K2HDKCサーバーノードと通信をするために、専用の制御ポートを使用します。
よって、インスタンスを起動するためにいくつかの事前設定が必要になります。
以下の手順は、事前設定を含めた説明をします。
試用環境を使っている場合は、予め事前設定されているため、先の手順に進んでください。
手順を進めるにあたり、Dashboardからログインし、K2HDKCクラスターと同じプロジェクトを選択してください。
6-2-1. K2HDKCスレーブノード用事前設定
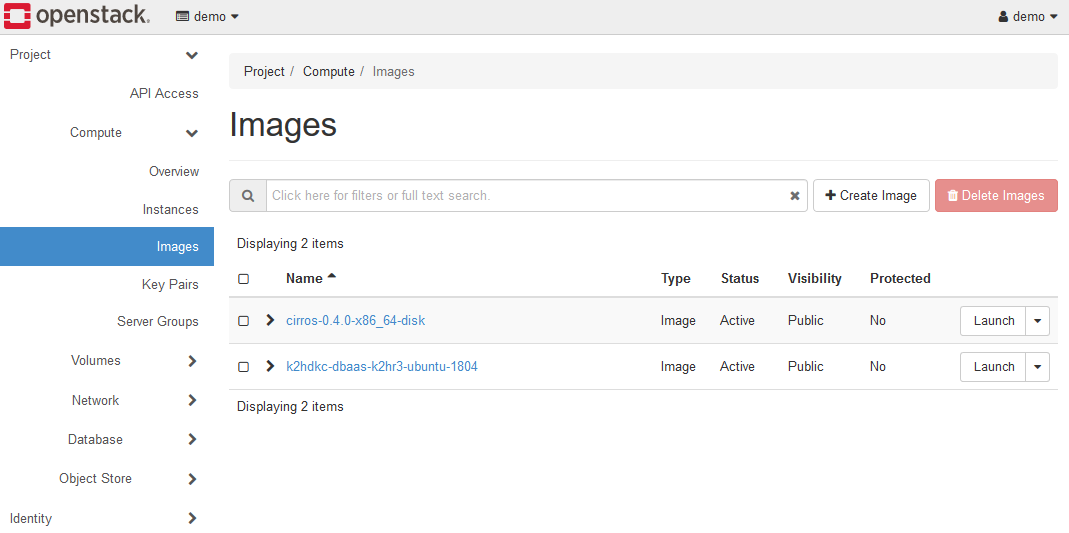
Compute > Images を開いてください。
予めK2HDKCスレーブノードを起動するためのOSイメージが存在することを確認してください。
OSイメージは、K2HDKCがサポートするOSをお使いください。
試用環境を使っている場合は、k2hdkc-dbaas-k2hr3-ubuntu-2204というUbuntu 22.04のイメージが存在しますので、これを利用します。
次に、K2HDKCスレーブノードがアクセスされる専用の制御ポートを許可するようにセキュリティグループを追加します。
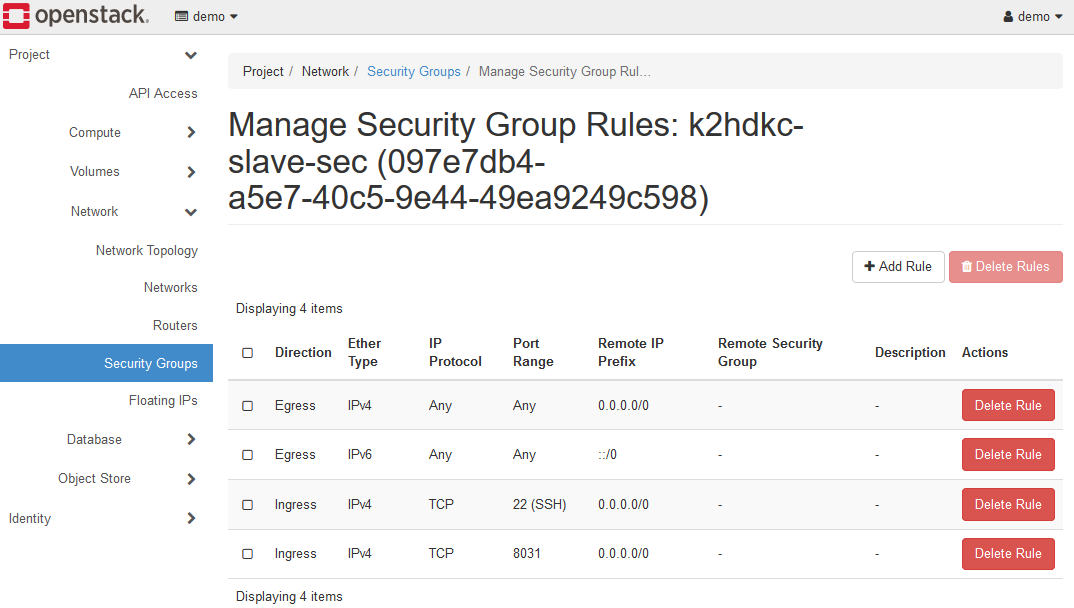
上記のように、TCP 8031ポートをANYのIngressで登録してください。
このドキュメントの手順では、SSHログインをしますので、TCP 22(SSH)ポートも同様に登録します。
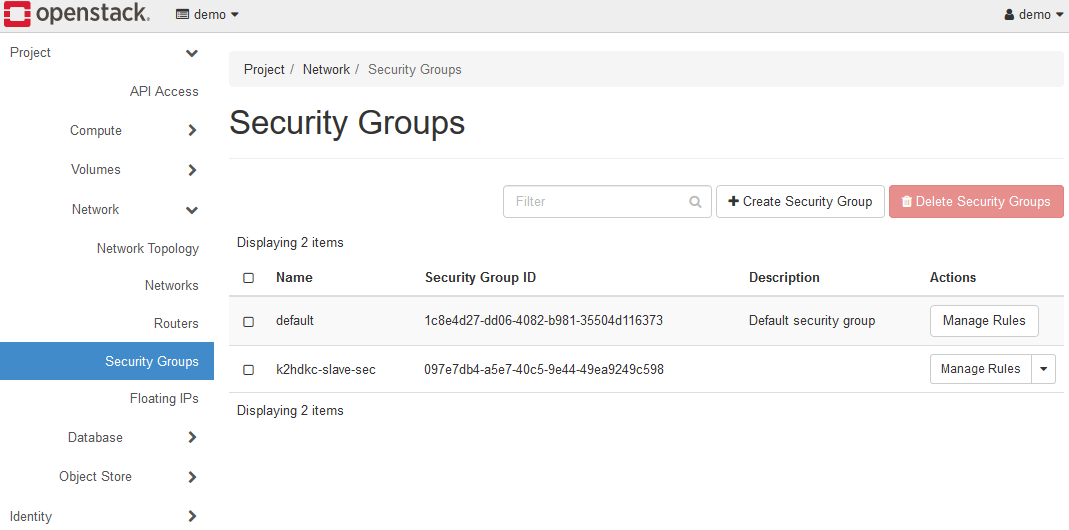
なお、試用環境を使っている場合は、予めk2hdkc-slave-secというセキュリティグループが登録されていますので、この登録は不要です。
登録されたセキュリティグループは、Network > Security Groupsで確認できます。
以上で事前設定は完了となります。
6-2-2. K2HDKCスレーブノード起動
Compute > instances を選択してください。
Database > Instancesではないので、注意してください。
Launch Instanceボタンをクリックして、Launch Instanceダイアログを表示してください。
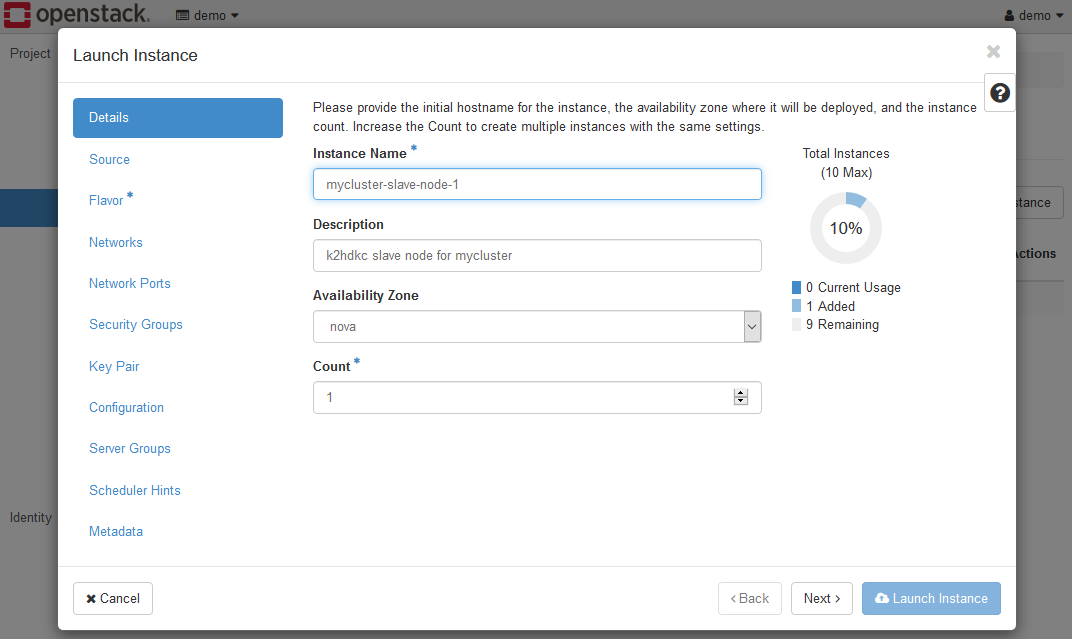
通常のインスタンス起動と同様に設定していきます。
各ページのK2HDKCスレーブノードに関連する設定を以下に示します。
- Details
インスタンス名などを設定してください。特にK2HDKCスレーブノードに特化した項目はありません。 - Source
K2HDKCスレーブノード用のOSイメージを選択してください。試用環境の場合は、k2hdkc-dbaas-k2hr3-ubuntu-2204を選択します。 - Flavor
準備したOSイメージなどに応じて、フレーバーを選択してください。試用環境の場合は、ds2Gを選択します。 - Networks
環境に応じて設定してください。試用環境の場合は、privateが選択されている状態にします。 - Security Groups
K2HDKCスレーブノード用のセキュリティグループを選択してください。試用環境の場合は、k2hdkc-slave-secを選択します。 - Key Pair
ログインをする場合には設定してください。 - Network Ports / Server Groups / Scheduler Hints / Metadata
環境に応じて設定してください。試用環境の場合は、未設定のままとします。 - Configuration
K2HR3から取得したUser Data Scriptの値を設定してください。
インスタンスの起動で重要なのは、Configurationページの設定です。
以下に示すように、K2HR3から取得したUser Data Scriptの値を設定してください。
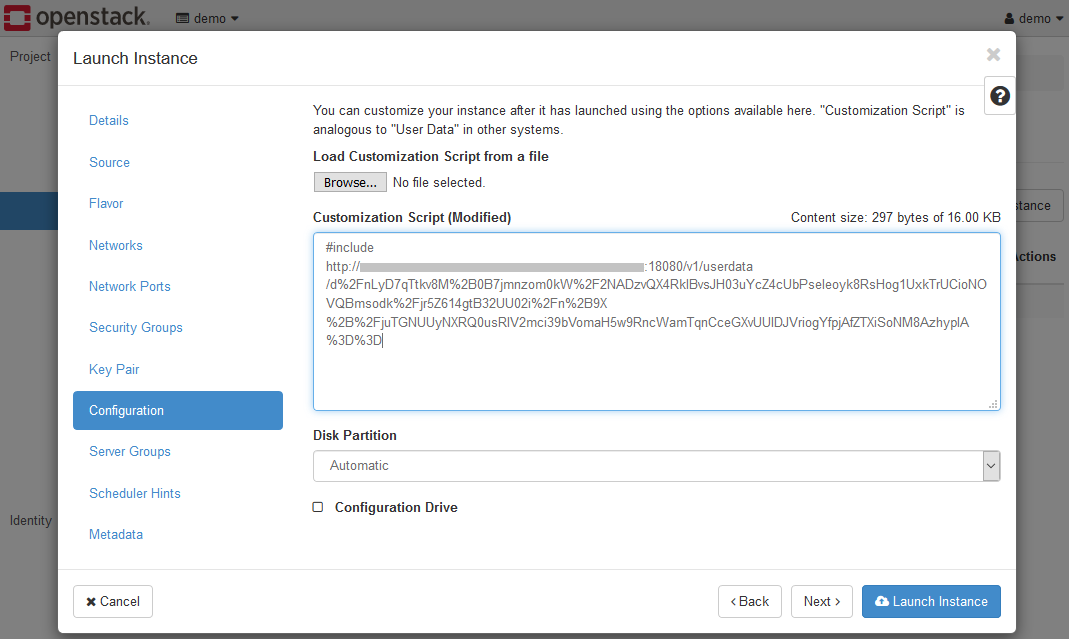
全てを設定したら、Launchボタンをクリックすると、インスタンスが起動します。
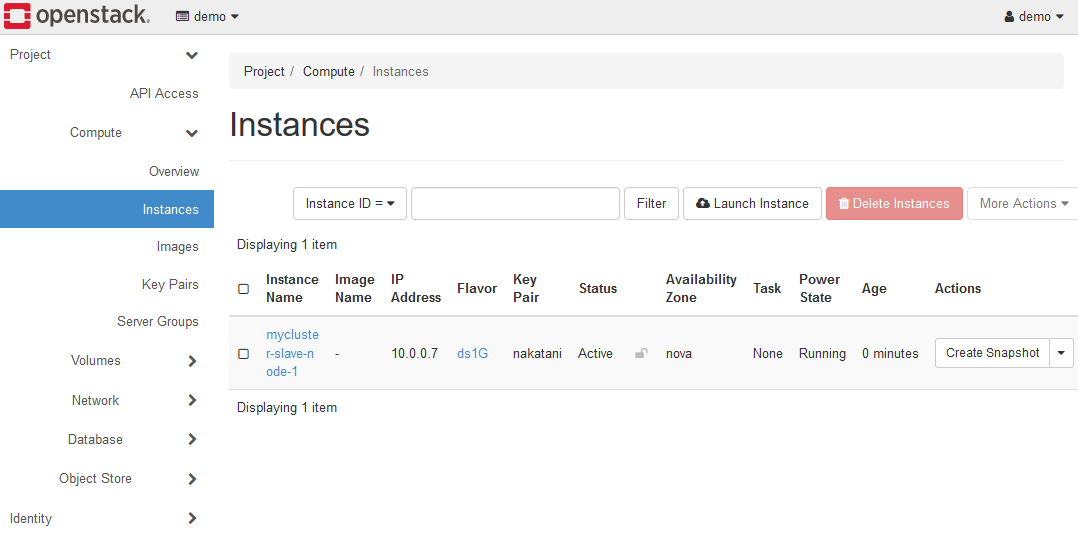
6-3. K2HDKCスレーブノードの確認
K2HDKCスレーブノード用のインスタンスが起動したら、K2HDKCスレーブノードを確認します。
インスタンスは、K2HDKCスレーブノード用に以下の状態で起動されています。
- K2HDKCスレーブノードとして必要となるプログラムがインストールされた状態
- K2HDKCスレーブノード用の設定ファイルとその自動更新サービスが登録された状態
ただし、インスタンスは起動していますが、K2HDKCスレーブノード用のプロセス等は何も起動していません。
設定ファイルの自動更新をするsystemd.serviceは登録・起動しています。
ここではK2HDKCスレーブノードのテストプロセスを起動し、K2HDKCクラスターとの接続を確認する方法を説明します。
確認には、CHMPXとK2HDKCに含まれるツールを利用します。
それらの利用方法については、それぞれのドキュメントを参照してください。
以下の確認手順の前に、K2HDKCスレーブノードにログイン(SSH)してください。
6-3-1. 設定ファイルの確認
K2HDKCスレーブノード用のインスタンスが起動後、一定時間が経過すると以下のファイルが自動的に生成されます。
このファイルは、K2HR3システムから取得したRESOURCEデータであり、このインスタンス専用のファイルです。
- /etc/k2hdkc/slave.ini
$ ls -la /etc/k2hdkc/slave.ini -rw-r--r-- 1 root root 2015 Sep 29 05:08 /etc/k2hdkc/slave.ini
このファイルは、K2HDKCスレーブノードの設定ファイルであり、K2HDKCクラスターの拡張・縮小(サーバーノード数の変化)に応じて自動的に更新されます。(オートコンフィグレーション)
6-3-2. CHMPXプロセス起動
K2HDKCサーバーノードとの接続は、CHMPXプログラムが行います。
CHMPX のパッケージは、インスタンス起動時にインストールされています。
K2HDKCクラスター(複数のサーバーノード)とこのインスタンス(スレーブノード)が正常に通信できるか確認します。
確認には、chmpxlinetoolコマンドを使います。
$ sudo chmpxlinetool -conf /etc/k2hdkc/slave.ini
-------------------------------------------------------
CHMPX CONTROL TOOL
-------------------------------------------------------
CHMPX library version : 1.0.83
Debug level : Error
Chmpx library debug level : Silent
Print command lap time : no
Command line history count : 1000
Chmpx nodes specified type : configuration file/json
Load Configuration : /etc/k2hdkc/slave.ini
-------------------------------------------------------
Chmpx nodes information at start
-------------------------------------------------------
Chmpx server nodes : 3
{
[0] = {
Chmpxid : 0x33ccc90bc9f9ff25
Hostname : host-10-0-0-19.openstacklocal
Control Port : 8021
CUK : 93fb0cf2-e336-4b8a-9ed9-4d53e1903503
Control Endpoints :
Custom ID Seed : server-node-2.novalocal
}
[1] = {
Chmpxid : 0x5c98c2baab77d132
Hostname : host-10-0-0-46.openstacklocal
Control Port : 8021
CUK : cfd6fcc4-cd7f-4ba2-852e-c517dfce1913
Control Endpoints :
Custom ID Seed : server-node-1.novalocal
}
[2] = {
Chmpxid : 0xc1bfd6fc9974f778
Hostname : host-10-0-0-52.openstacklocal
Control Port : 8021
CUK : 3c82ebee-1d8d-4d1c-b6eb-691a05c4c0b0
Control Endpoints :
Custom ID Seed : server-node-3.novalocal
}
}
Chmpx slave nodes : 1
{
[0] = {
Chmpxid : 0x0ad1f1a4b41b8dfd
Hostname : 10.0.0.10
Control Port : 8031
CUK : 03c5220e-67a7-4e5f-9a8b-8ae746a08497
Control Endpoints :
Custom ID Seed : mycluster-slave-node-1
}
}
-------------------------------------------------------
CLT> check
OK 10.0.0.19:8021:93fb0cf2-e336-4b8a-9ed9-4d53e1903503:server-node-2.novalocal: = {
status = [SERVICE IN] [UP] [n/a] [Nothing][NoSuspend]
hash(pending) = 0x1(0x1)
sockcount(in/out) = 1/1
lastupdatetime = 2020-09-29 04h 11m 43s 431ms 284us(26866240190846132)
}
OK 10.0.0.46:8021:cfd6fcc4-cd7f-4ba2-852e-c517dfce1913:server-node-1.novalocal: = {
status = [SERVICE IN] [UP] [n/a] [Nothing][NoSuspend]
hash(pending) = 0(0)
sockcount(in/out) = 1/1
lastupdatetime = 2020-09-29 05h 28m 06s 69ms 395us(26866317080465171)
}
OK 10.0.0.52:8021:3c82ebee-1d8d-4d1c-b6eb-691a05c4c0b0:server-node-3.novalocal: = {
status = [SERVICE IN] [UP] [n/a] [Nothing][NoSuspend]
hash(pending) = 0x2(0x2)
sockcount(in/out) = 1/1
lastupdatetime = 2020-09-29 04h 11m 43s 682ms 946us(26866240191097794)
}
CLT> exit
Quit.
上記のようにchmpxlinetoolを起動し、そのコマンドプロンプトにcheckと入力します。
全ての結果が、OKであれば、問題なく通信できます。
確認が終わったら、CHMPX プログラムを起動します。
以下のようにして起動します。
$ sudo chmpx -conf /etc/k2hdkc/slave.ini &
正常に起動するとK2HDKCサーバーノードと通信できるようになります。
6-3-3. テストプログラムの起動
K2HDKCクラスターと通信し、スレーブノード上でK2HDKCの動作を確認するため、k2hdkclinetoolテストプログラムを使います。
このプログラムは、K2HDKCパッケージに属しており、インスタンスの起動時にインストールされています。
以下のようにk2hdkclinetoolを起動します。
$ sudo k2hdkclinetool -conf /etc/k2hdkc/slave.ini
-------------------------------------------------------
K2HDKC LINE TOOL
-------------------------------------------------------
K2HDKC library version : 0.9.30
K2HDKC API : C++
Communication log mode : no
Debug mode : silent
Debug log file : not set
Print command lap time : no
Command line history count : 1000
Chmpx parameters:
Configuration : /etc/k2hdkc/slave.ini
Control port : 0
CUK :
Permanent connect : no
Auto rejoin : no
Join giveup : no
Cleanup backup files : yes
-------------------------------------------------------
K2HDKC>
コマンドプロンプトに、status nodeと入力してください。
K2HDKC> status node
K2HDKC server node count = 3
< chmpxid >[< base hash >]( server name ) : area element page (k2hash size/ file size )
----------------+-----------------+-------------------------:-----+-------+----+-------------------------
33ccc90bc9f9ff25[0000000000000001](10.0.0.19 ) : 0% 0% 0% (298905600 / 298905600)
5c98c2baab77d132[0000000000000000](10.0.0.46 ) : 0% 0% 0% (298905600 / 298905600)
c1bfd6fc9974f778[0000000000000002](10.0.0.52 ) : 0% 0% 0% (298905600 / 298905600)
K2HDKCクラスターのサーバーノードの情報を表示できます。
最後に、データの読み書きのテストをします。
K2HDKC> set test-key test-value
K2HDKC> print test-key
"test-key" => "test-value"
kest-keyを書き込み、それを読み出せたら、このインスタンスは問題なくK2HDKCスレーブノードとして利用できます。
以上で、正常にK2HDKCクラスターと接続したK2HDKCスレーブノードの動作確認の完了です。
Usage Usage DBaaS CLI